void GlobalArray::absValue() const
Collective on the processor group inferred from the arguments.
Take the element-wise absolute value of the array.
void GlobalArray::absValuePatch(int *lo, int *hi) const
void GlobalArray::absValuePatch(int64_t *lo, int64_t *hi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| lo | lower corner patch coordinates | input | |
| hi | upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Take the element-wise absolute value of the patch.
void GlobalArray::acc(int lo[], int hi[], void *buf,
int ld[], void *alpha) const
void GlobalArray::acc(int64_t lo[], int64_t hi[], void *buf,
int64_t ld[], void *alpha) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for array section | input |
| int* | hi[ndim] | array of ending indices for array section | input |
| void* | buf | pointer to the local buffer array | input |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
| void* | alpha | scale factor (double/double complex/long *) | input |
One-sided (non-collective).
Combines data from local array buffer with data in the global array section. The local array is assumed to be have the same number of dimensions as the global array.
global array section (lo[],hi[]) += *alpha * buffer
void GlobalArray::access(int lo[], int hi[], void *ptr, int ld[]) const
void GlobalArray::access(int64_t lo[], int64_t hi[], void *ptr, int64_t ld[]) cons
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for array section | input |
| int* | hi[ndim] | array of ending indices for array section | input |
| void** | ptr | points to location of first element in patch | output |
| int* | ld[ndim-1] | leading dimensions for the pacth elements | output |
Local operation.
Provides access to the specified patch of a global array. Returns array of leading dimensions ld and a pointer to the first element in the patch. This routine allows to access directly, in place elements in the local section of a global array. It useful for writing new GA operations. A call to access normally follows a previous call to distribution that returns coordinates of the patch associated with a processor. You need to make sure that the coordinates of the patch are valid (test values returned from distribution).
Each call to access has to be followed by a call to either release or releaseUpdate. You can access in this fashion only local data. Since the data is shared with other processes, you need to consider issues of mutual exclusion.
void GlobalArray::accessBlock(int idx, void *ptr, int ld[]) const
void GlobalArray::accessBlock(int64_t idx, void *ptr, int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | idx | index of block | input |
| void** | ptr | points to location of first element in patch | output |
| int* | ld[ndim-1] | leading dimensions for the pacth elements | output |
Local operation.
This function can be used to gain direct access to the data represented by a single block in a global array with a block-cyclic data distribution. The index idx is the index of the block in the array assuming that blocks are numbered sequentially in a column-major order. A quick way of determining whether a block with index idx is held locally on a processor is to calculate whether idx\%nproc equals the processor ID, where nproc is the total number of processors. Once the pointer has been returned, local data can be accessed as described in the documentation for access. Each call to accessBlock should be followed by a call to either ReleaseBlock or releaseUpdateBlock.
void GlobalArray::accessBlockGrid(int index[], void *ptr, int ld[]) const
void GlobalArray::accessBlockGrid(int64_t index[], void *ptr, int64_t ld[])
const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | index[ndim] | indices of block in processor grid | input |
| void** | ptr | points to location of first element in patch | output |
| int* | ld[ndim-1] | leading dimensions for the pacth elements | output |
Local operation.
This function can be used to gain direct access to the data represented by a single block in a global array with a SCALAPACK block-cyclic data distribution that is based on an underlying processor grid. The subscript array contains the subscript of the block in the array of blocks. This subscript is based on the location of the block in a grid, each of whose dimensions is equal to the number of blocks that fit along that dimension. Once the index has been returned, local data can be accessed as described in the documentation for access. Each call to accessBlockGrid should be followed by a call to either releaseBlockGrid or releaseUpdateBlockGrid.
void GlobalArray::accessBlockSegment(int index, void *ptr,
int *len) const
void GlobalArray::accessBlockSegment(int index, void *ptr,
int64_t *len) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | index | processor ID | input |
| void** | ptr | points to location of first element | output |
| int* | len | length of locally held data | output |
Local operation.
This function can be used to gain access to the all the locally held data on a particular processor that is associated with a block-cyclic distributed array. Once the index has been returned, local data can be accessed as described in the documentation for access. The parameter len is the number of data elements that are held locally. The data inside this segment has a lot of additional structure so this function is not generally useful to developers. It is primarily used inside the GA library to implement other GA routines. Each call to accessBlockSegment should be followed by a call to either releaseBlockSegment or releaseUpdateBlockSegment.
void GlobalArray::accessGhostElement(void *ptr, int subscript[],
int ld[]) const
void GlobalArray::accessGhostElement(void *ptr, int64_t subscript[],
int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| void** | ptr | index pointing to location of element indexed by subscript[] | output |
| int* | subscript[ndim] | array of integers that index desired element | input |
| int* | ld[ndim-1] | array of strides for local data patch. These include ghost cell widths. | output |
Local operation.
This function can be used to return a pointer to any data element in the locally held portion of the global array and can be used to directly access ghost cell data. The array subscript refers to the local index of the element relative to the origin of the local patch (which is assumed to be indexed by (0,0,...)).
void GlobalArray::accessGhosts(int dims[], void *ptr, int ld[]) const
void GlobalArray::accessGhosts(int64_t dims[], void *ptr, int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | dims[ndim] | array of dimensions of local patch, including ghost cells | output |
| void** | ptr | returns an index corresponding to the origin the global array patch held locally on the processor | output |
| int* | ld[ndim-1] | physical dimensions of the local array patch, including ghost cells | output |
Local operation.
Provides access to the local patch of the global array. Returns leading dimension ld and and pointer for the data. This routine will provide access to the ghost cell data residing on each processor. Calls to accessGhosts should normally follow a call to distribution that returns coordinates of the visible data patch associated with a processor. You need to make sure that the coordinates of the patch are valid (test values returned from distribution).
You can only access local data.
void GlobalArray::add(void *alpha, const GlobalArray * g_a, void *beta, const GlobalArray * g_b) const
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | alpha | scale factor | input |
| int | g_a | array | input |
| void* | beta | scale factor | input |
| int | g_b | array | input |
Collective on the processor group inferred from the arguments.
The arrays (which must be the same shape and identically aligned) are added together element-wise.
c = alpha * a + beta * b;
The result (c) may replace one of the input arrays (a/b).
void GlobalArray::addConstant(void* alpha) const
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | alpha | double/complex/int/long/float* constant to be added | input |
Collective on the processor group inferred from the arguments.
Add the constant pointed by alpha to each element of the array.
void GlobalArray::addConstantPatch(int *lo, int *hi, void *alpha) const
void GlobalArray::addConstantPatch(int64_t *lo, int64_t *hi, void *alpha) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo | lower corner patch coordinates | input |
| int* | hi | upper corner patch coordinates | input |
| void* | alpha | double/complex/int/long/float constant to be added | input |
Collective on the processor group inferred from the arguments.
Add the constant pointed by alpha to each element of the patch.
void GlobalArray::addDiagonal(const GlobalArray * g_v) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_v | global array containing diagonal elements to be added | input |
Collective on the processor group inferred from the arguments.
Adds the elements of the vector g_v to the diagonal of this matrix g_a.
void GlobalArray::addPatch(void *alpha, const GlobalArray * g_a, int alo[],
int ahi[],void *beta, const GlobalArray * g_b,
int blo[], int bhi[], int clo[], int chi[]) const
void GlobalArray::addPatch(void *alpha, const GlobalArray * g_a, int64_t alo[],
int64_t ahi[], void *beta, const GlobalArray * g_b,
int64_t blo[], int64_t bhi[], int64_t clo[],
int64_t chi[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | alpha | scale factor | input |
| int | g_a | global array | input |
| int* | alo | patch of g_a | input |
| int* | ahi | patch of g_a | input |
| void* | beta | scale factor | input |
| int | g_b | global array | input |
| int* | blo | patch of g_b | input |
| int* | bhi | patch of g_b | input |
| int* | clo | patch of this GlobalArray | input |
| int* | chi | patch of this GlobalArray | input |
Collective on the processor group inferred from the arguments.
Patches of arrays (which must have the same number of elements) are added together element-wise.
c[ ][ ] = alpha * a[ ][ ] + beta * b[ ][ ]
void GlobalArray::allocGatscatBuf(int nelems) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | nelems | maximum number of elements to scatter/gather | input |
Local operation.
This function can be used to enhance the performance when the gather/scatter operations are being called multiple times in succession. If the maximum number of elements being called in any gather/scatter operation is known prior to executing a code segment, then some internal buffers used in the gather/scatter operations can be allocated beforehand instead of at every individual call. This can result in substantial performance boosts in some cases. When the buffers are no longer needed they can be removed using the corresponding free call.
int GlobalArray::allocate() const
Collective on the processor group inferred from the arguments.
This function allocates the memory for the global array handle originally obtained using the GA_Create_handle function. At a minimum, the GA_Set_data function must be called before the memory is allocated. Other GA_Set_xxx functions can also be called before invoking this function.
Returns True if allocation of g_a was successful.
void GAServices::brdcst(void *buf, int lenbuf, int root)
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | buf[lenbuf] | data | input/output |
| int | lenbuf | length of buffer | input |
| int | root | root process | input |
Collective on the world processor group.
Broadcast from process root to all other processes a message of length lenbuf.
This is operation is provided only for convenience purposes: it is available regardless of the message-passing library that GA is running.
void GlobalArray::checkHandle(char* string) const
| Type | Name | Description | Intent |
|---|---|---|---|
| string | message | input |
Local operation.
Check that the global array handle g_a is valid ... if not, call ga_error with the string provided and some more info.
int GAServices::clusterNnodes()
Local operation.
This functions returns the total number of nodes that the program is running on. On SMP architectures, this will be less than or equal to the total number of processors.
int GAServices::clusterNodeid()
Local operation.
This function returns the node ID of the process. On SMP architectures with more than one processor per node, several processes may return the same node id.
int GAServices::clusterNprocs(int inode)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | inode | node id | input |
Local operation.
This function returns the number of processors available on node inode.
int GAServices::clusterProcNodeid(int iproc)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | iproc | process id | input |
Local operation.
This function returns the node ID of the specified process proc. On SMP architectures with more than one processor per node, several processes may return the same node id.
int GAServices::clusterProcid(int inode, int iproc)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | inode | node id | input |
| int | iproc | processor id | input |
Local operation.
This function returns the processor id associated with node inode and the local processor ID iproc. If node inode has N processors, then the value of iproc lies between 0 and N-1.
int GlobalArray::compareDistr(const GlobalArray *g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | GlobalArray to compare against | input |
| int | 0 if distributions are identical | output |
Collective on the processor group inferred from the arguments.
Compares distributions of two global arrays. Returns 0 if distributions are identical and 1 when they are not.
void GlobalArray::copy(const GlobalArray *g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | GlobalArray to copy | input |
Collective on the processor group inferred from the arguments.
Copies elements in array represented by g_a into the array represented by g_b. The arrays must be the same type, shape, and identically aligned.
For patch operations, the patches of arrays may be of different shapes but must have the same number of elements. Patches must be nonoverlapping (if g_a=g_b). Transposes are allowed for patch operations.
void GlobalArray::copyPatch(char trans, const GlobalArray* ga, int alo[],
int ahi[], int blo[], int bhi[]) const
void GlobalArray::copyPatch(char trans, const GlobalArray* ga, int64_talo[],
int64_t ahi[], int64_t blo[], int64_t bhi[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| char | trans | use transpose operator | input |
| int | ga | global array | input |
| int* | alo | ga patch coordinates | input |
| int* | ahi | ga patch coordinates | input |
| int* | blo | this GlobalArray's patch coordinates | input |
| int* | bhi | this GlobalArray's patch coordinates | input |
Collective on the processor group inferred from the arguments.
Copies elements in a patch of one array into another one. The patches of arrays may be of different shapes but must have the same number of elements. Patches must be non-overlapping (if g_a=g_b).
trans = `N' or `n' means that the transpose operator should
not be applied.
trans = `T' or `t' means that transpose operator should be applied.
GlobalArray::GlobalArray(int type, int ndim, int dims[],
char *arrayname, int chunk[])
GlobalArray * GAServices::createGA(int type, int ndim, int dims[],
char *arrayname, int chunk[])
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | data type(C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims[ndim] | array of dimensions | input |
| char* | arrayname | a unique character string | input |
| int* | chunk[ndim] | array of chunks, each element specifies minimum size that given dimensions should be chunked up into | input |
| GlobalArray | instance | output |
Collective on the default processor group.
Creates an ndim-dimensional array using the regular distribution model and returns an integer handle representing the array.
The array can be distributed evenly or not. The control over the distribution is accomplished by specifying chunk (block) size for all or some of array dimensions. For example, for a 2-dimensional array, setting chunk[0]=dim[0] gives distribution by vertical strips (chunk[0]*dims[0]); setting chunk[1]=dim[1] gives distribution by horizontal strips (chunk[1]*dims[1]). Actual chunks will be modified so that they are at least the size of the minimum and each process has either zero or one chunk. Specifying chunk[i] as less than 1 will cause that dimension to be distributed evenly.
As a convenience, when chunk is specified as NULL, the entire array is distributed evenly.
Return value: a non-zero array handle means the call was succesful.
GlobalArray::GlobalArray(int type, int ndim, int dims[], char *arrayname,
int chunk[],PGroup* p_handle)
GlobalArray::GlobalArray(int type, int ndim, int64_t dims[], char *arrayname,
int64_t chunk[], PGroup* p_handle)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | data type(C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims[ndim] | array of dimensions | input |
| char* | arrayname | a unique character string | input |
| int* | chunk[ndim] | array of chunks, each element specifies minimum size that given dimensions should be chunked up into | input |
| PGroup* | p_handle | processor group handle | input |
| GlobalArray | instance | output |
Collective on the default processor group.
Creates an ndim-dimensional array using the regular distribution model but with an explicitly specified processor group handle and returns an integer handle representing the array.
This call is essentially the same as the base GlobalArray constructor, except for the processor group handle p_handle. It can also be used to create mirrored arrays.
Return value: a non-zero array handle means the call was succesful.
GlobalArray::GlobalArray(int type, int ndim, int dims[], int width[],
char *arrayname, int chunk[], char ghosts)
GlobalArray::GlobalArray(int type, int ndim, int64_t dims[], int64_t width[],
char *arrayname, int64_t chunk[], char ghosts)
GlobalArray * GAServices::createGA_Ghosts(int type, int ndim, int dims[],
int width[], char *array_name,
int chunk[])
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | data type (C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims[ndim] | array of dimensions | input |
| int* | width[ndim] | array of ghost cell widths | input |
| char* | array_name | a unique character string | input |
| int* | chunk[ndim] | array of chunks, each element specifies minimum size that given dimensions should be chunked up into | input |
| char | ghosts | this is a dummy parameter: added to increase the number of arguments, in order to avoid the conflicts among constructors. (ghosts = 'g' or 'G') | input |
Collective on the default processor group.
Creates an ndim-dimensional array with a layer of ghost cells around the visible data on each processor using the regular distribution model and returns an integer handle representing the array.
The array can be distributed evenly or not evenly. The control over the distribution is accomplished by specifying chunk (block) size for all or some of the array dimensions. For example, for a 2-dimensional array, setting chunk(1)=dim(1) gives distribution by vertical strips (chunk(1)*dims(1)); setting chunk(2)=dim(2) gives distribution by horizontal strips (chunk(2)*dims(2)). Actual chunks will be modified so that they are at least the size of the minimum and each process has either zero or one chunk. Specifying chunk(i) as < 1 will cause that dimension (i-th) to be distributed evenly. The width of the ghost cell layer in each dimension is specified using the array width(). The local data of the global array residing on each processor will have a layer width[n] ghosts cells wide on either side of the visible data along the dimension n.
Return value: a non-zero array handle means the call was successful.
GlobalArray::GlobalArray(int type, int ndim, int dims[], int width[],
char *arrayname, int chunk[], PGroup* p_handle,
char ghosts)
GlobalArray::GlobalArray(int type, int ndim, int64_t dims[], int64_t width[],
char *arrayname, int64_t chunk[], PGroup* p_handle,
char ghosts)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | data type (C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims[ndim] | array of dimensions | input |
| int* | width[ndim] | array of ghost cell widths | input |
| char* | array_name | a unique character string | input |
| int* | chunk[ndim] | array of chunks, each element specifies minimum size that given dimensions should be chunked up into | input |
| int | p_handle | processor group handle | input |
| char | ghosts | this is a dummy parameter: added to increase the number of arguments, inorder to avoid the conflicts among constructors. (ghosts = 'g' or 'G') | input |
Collective on the default processor group.
Creates an ndim-dimensional array with a layer of ghost cells around the visible data on each processor using the regular distribution model and an explicitly specified processor list and returns an integer handle representing the array.
This call is essentially the same as the NGA_Create_ghosts call, except for the processor list handle p_handle. It can be used to create mirrored arrays.
Return value: a non-zero array handle means the call was successful.
GlobalArray::GlobalArray(int type, int ndim, int dims[], int width[],
char *arrayname,
int block[], int maps[], char ghosts);
GlobalArray::GlobalArray(int type, int ndim, int64_t dims[],
int64_t width[], char *arrayname,
int64_t block[], int64_t maps[], char ghosts)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | data type (C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims[ndim] | array of dimensions | input |
| int* | width[ndim] | array of ghost cell widths | input |
| char* | arrayname | a unique character string | input |
| int* | block[ndim] | no. of blocks each dimension is divided into | input |
| int* | maps[s] | starting index for for each block; the size s is a sum of all elements of nblock array | input |
| char | ghosts | this is a dummy parameter: added to increase the number of arguments, inorder to avoid the conflicts among constructors. (ghosts = 'g' or 'G') | input |
Collective on the default processor group.
Creates an array with ghost cells by following the user-specified distribution and returns an integer handle representing the array.
The distribution is specified as a Cartesian product of distributions for each dimension.
Figure "crghostir" below demonstrates distribution of a 2-dimensional array 8x10 on 6 (or more) processors.
nblock[2]={3,2}, the size of map array is s=5 and the array map contains the following elements map={0,2,6, 0, 6}. The distribution is nonuniform because, P1 and P4 get 20 elements each and processors P0, P2, P3, and P5 only 10 elements each.
The array width is used to control the width of the ghost cell boundary around the visible data on each processor. The local data of the Global Array residing on each processor will have a layer width[n] ghosts cells wide on either side of the visible data along the dimension n.
Return value: a non-zero array handle means the call was succesful.
GlobalArray::GlobalArray(int type, int ndim, int dims[], int width[],
char *arrayname, int block[], int maps[],
PGroup* p_handle, char ghosts)
GlobalArray::GlobalArray(int type, int ndim, int64_t dims[],
int64_t width[], char *arrayname,
int64_t block[], int64_t maps[],
PGroup* p_handle,char ghosts)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | data type (C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims[ndim] | array of dimensions | input |
| int* | width[ndim] | array of ghost cell widths | input |
| char* | arrayname | a unique character string | input |
| int* | block[ndim] | no. of blocks each dimension is divided into | input |
| int* | maps[s] | starting index for for each block; the size s is a sum of all elements of nblock array | input |
| PGroup* | p_handle | processor group handle | input |
| char | ghosts | this is a dummy parameter: added to increase the number of arguments, inorder to avoid the conflicts among constructors. (ghosts = 'g' or 'G') | input |
Collective on the default processor group.
Creates an array with ghost cells by following the user-specified distribution and returns an integer handle representing the array. The user can specify that the array is created on a particular processor group.
This call is similar to the constructor for creating irregular distributions with ghost cells.
Return value: a non-zero array handle means the call was succesful.
GlobalArray::GlobalArray()
Collective on the default processor group.
This function returns a Global Array handle that can then be used to create a new Global Array. This is part of a new API for creating Global Arrays that is designed to replace the old interface built around the NGA_Create_xxx calls. The sequence of operations is to begin with a call to GA_Greate_handle to get a new array handle. The attributes of the array, such as dimension, size, type, etc., can then be set using successive calls to the GA_Set_xxx subroutines. When all array attributes have been set, the GA_Allocate subroutine is called and the Global Array is actually created and memory for it is allocated.
GlobalArray * GAServices::createGA(int type, int ndim, int dims[],
char *arrayname,
int block[], int maps[])
GlobalArray::GlobalArray(int type, int ndim, int dims[], char *arrayname,
int block[],int maps[]);
GlobalArray::GlobalArray(int type, int ndim, int64_t dims[],
char *arrayname, int64_t block[],
int64_t maps[])
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | MA data type (C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims | array of dimension values | input |
| char* | arrayname | a unique character string | input |
| int* | block[ndim] | no. of blocks each dimension is divided into | input |
| int* | maps[s] | starting index for for each block; the size s is a sum all elements of nblock array | input |
Collective on the default processor group.
Creates an array by following the user-specified distribution and returns an integer handle representing the array.
The distribution is specified as a Cartesian product of distributions for each dimension. The array indices start at 0. For example, Figure "crirreg" below demonstrates the distribution of a 2-dimensional 8x10 array on 6 (or more) processors.
nblock[2]={3,2}, the size of the map array is s=5 and the array map contains the following elements map={0,5,0,2,6}. The distribution is nonuniform because P1 and P4 get 20 elements each and processors P0, P2, P3, and P5 only 10 elements each.
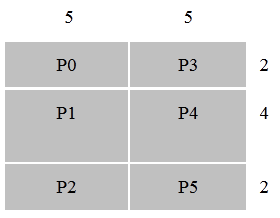
Return value: a non-zero array handle means the call was succesful.
GlobalArray:: GlobalArray(int type, int ndim, int dims[],
char *arrayname, int block[],
int maps[], PGroup* p_handle)
GlobalArray:: GlobalArray(int type, int ndim, int64_t dims[],
char *arrayname,
int64_t block[], int64_t maps[],
PGroup* p_handle)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | type | MA data type (C_DBL,C_INT,C_DCPL,etc.) | input |
| int | ndim | number of array dimensions | input |
| int* | dims | array of dimension values | input |
| char* | arrayname | a unique character string | input |
| int* | block[ndim] | no. of blocks each dimension is divided into | input |
| int* | maps[s] | starting index for for each block; the size s is a sum all elements of nblock array | input |
| p_handle | processor group handle | input |
Collective on the default processor group.
Creates an array by following the user-specified distribution and an explicitly specified processor group handle and returns an integer handle representing the array.
This call is essentially the same as GlobalArray constructors, except for the processor group handle p_handle. It can also be used to create mirrored arrays.
Return value: a non-zero array handle means the call was succesful.
GAServices::createMutexes(int number)
| Type | Name | Description | Intent |
|---|---|---|---|
| number | of mutexes in mutex array | input |
Collective on the world processor group.
Creates a set containing the number of mutexes. Returns 0 if the operation succeeded or 1 if it has failed. Mutex is a simple synchronization object used to protect Critical Sections. Only one set of mutexes can exist at a time. An array of mutexes can be created and destroyed as many times as needed.
Mutexes are numbered: 0, ..., number-1.
Returns: True on success, False on failure
GlobalArray::~GlobalArray()
void GlobalArray::destroy()
Collective on the processor group inferred from the arguments.
Deallocates the array and frees any associated resources.
GAServices::destroyMutexes()
Collective on the world processor group.
Destroys the set of mutexes created with ga_create_mutexes. Returns 0 if the operation succeeded or 1 when failed.
void GlobalArray::diag(const GlobalArray *g_s,
GlobalArray *g_v, void *eval)
const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_s | Matrix to diagonalize | input |
| int | g_v | Global matrix to return evecs | input |
| void* | eval | Local array to return evals | input |
Collective on the processor group inferred from the arguments.
Solve the generalized eigenvalue problem returning all eigenvectors and values in ascending order. The input matrices are not overwritten or destroyed.
All eigen-values as a vector in ascending order.
void GlobalArray::diagReuse(int control, const GlobalArray *g_s,
GlobalArray *g_v, void *eval) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | control | Control flag | input |
| int | g_s | Matrix to diagonalize | input |
| int | g_v | Global matrix to return evecs | input |
| void* | eval | Local array to return evals | output |
Collective on the processor group inferred from the arguments.
Solve the generalized eigenvalue problem returning all eigenvectors and values in ascending order. Recommended for REPEATED calls if g_s is unchanged. Values of the control flag:
value action/purpose
0 indicates first call to the eigensolver
>0 consecutive calls (reuses factored g_s)
<0 only erases factorized g_s; g_v and eval unchanged
(should be called after previous use if another
eigenproblem, i.e., different g_a and g_s, is to
be solved)
The input matrices are not destroyed.
Returns: All eigen-values as a vector in ascending order.
void GlobalArray::diagStd(GlobalArray *g_v, void *eval) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_v | Global matrix to return evecs | output |
| void* | eval | Local array to return evals | output |
Collective on the processor group inferred from the arguments.
Solve the standard (non-generalized) eigenvalue problem returning all eigenvectors and values in the ascending order. The input matrix is neither overwritten nor destroyed.
Returns: all eigenvectors via the g_v global array, and eigenvalues as an array in ascending order
void GlobalArray::distribution(int me, int* lo, int* hi) const
void GlobalArray::distribution(int me, int64_t* lo, int64_t* hi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | iproc | process number | input |
| int* | lo[ndim] | array of starting indices for array section | output |
| int* | hi[ndim] | array of ending indices for array section | output |
Local operation.
This function returns the bounding indices of the block owned by the process iproc. These indices are inclusive.
If no array elements are owned by process iproc, the range is returned as lo[]=-1 and hi[]= -2 for all dimensions.
int GlobalArray::idot(const GlobalArray * g_a) const
long GlobalArray::ldot(const GlobalArray * g_a) const
float GlobalArray::fdot(const GlobalArray * g_a) const
double GlobalArray::ddot(const GlobalArray * g_a) const
double complex GlobalArray::zdot(const GlobalArray * g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| GlobalArray* | g_a | the other array | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise dot product of the two arrays which must be of the same types and same number of elements.
Return value = SUM_ij a(i,j)*b(i,j)
double GlobalArray::ddotPatch(char ta, int alo[], int ahi[],
const GlobalArray * g_a, char tb, int blo[],
int bhi[]) const
double GlobalArray::ddotPatch(char ta, int64_t alo[], int64_t ahi[],
const GlobalArray * g_a, char tb,
int64_t blo[], int64_t bhi[]) const
float GlobalArray::fdotPatch(char ta, int alo[], int ahi[],
const GlobalArray * g_a, char tb, int blo[],
int bhi[]) const
float GlobalArray::fdotPatch(char ta, int64_t alo[], int64_t ahi[],
const GlobalArray * g_a, char tb, int64_t blo[],
int64_t bhi[]) const
double complex GlobalArray::zdotPatch(char ta, int alo[], int ahi[],
const GlobalArray * g_a, char tb,
int blo[], int bhi[]) const
double complex GlobalArray::zdotPatch(char ta, int64_t alo[], int64_t ahi[],
const GlobalArray * g_a, char tb,
int64_t blo[], int64_t bhi[]) const
long GlobalArray::idotPatch(char ta, int alo[], int ahi[],
const GlobalArray * g_a, char tb, int blo[],
int bhi[]) const
long GlobalArray::idotPatch(char ta, int64_t alo[], int64_t ahi[],
const GlobalArray * g_a, char tb, int64_t blo[],
int64_t bhi[]) const
long GlobalArray::ldotPatch(char ta, int alo[], int ahi[],
const GlobalArray * g_a, char tb, int blo[],
int bhi[]) const
long GlobalArray::ldotPatch(char ta, int64_t alo[], int64_t ahi[],
const GlobalArray * g_a, char tb, int64_t blo[],
int64_t bhi[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| char | ta | transpose flags | input |
| int* | alo | g_a patch coordinates | input |
| int* | ahi | g_a patch coordinates | input |
| int | g_a | global array | input |
| char | tb | transpose flags | input |
| int* | blo | g_b patch coordinates | input |
| int* | bhi | g_b patch coordinates | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise dot product of the two (possibly transposed) patches which must be of the same type and have the same number of elements.
GlobalArray::GlobalArray(const GlobalArray &g_a, char *arrayname)
GlobalArray::GlobalArray(const GlobalArray &g_a)
GlobalArray * GAServices::createGA(const GlobalArray *g_b, char *arrayname)
GlobalArray * GAServices::createGA(const GlobalArray &g_b)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_b | integer handle for reference array | input |
| char* | arrayname | a character string | input |
Collective on the processor group inferred from the arguments.
Creates a new array by applying all the properties of another existing array. It returns an array handle.
Return value: a non-zero array handle means the call was succesful.
void GlobalArray::elemDivide(const GlobalArray * g_a,
const GlobalArray * g_b) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | GlobalArray | input |
| const GlobalArray* | g_b | GlobalArray | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise quotient of the two arrays which must be of the same types and same number of elements. For two-dimensional arrays,
c(i,j) = a(i,j)/b(i,j)
The result (c) may replace one of the input arrays (a/b). If one of the elements of array g_b is zero, the quotient for the element of g_c will be set to GA_NEGATIVE_INFINITY.
void GlobalArray::elemDividePatch(
const GlobalArray * g_a, int *alo, int *ahi,
const GlobalArray * g_b, int *blo, int *bhi,
int *clo, int *chi) const
void GlobalArray::elemDividePatch(
const GlobalArray * g_a, int64_t *alo, int64_t *ahi,
const GlobalArray * g_b, int64_t *blo, int64_t *bhi,
int64_t *clo, int64_t *chi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | global array | input |
| int | g_b | global array | input |
| int* | alo | g_a lower corner patch coordinates | input |
| int* | ahi | g_a upper corner patch coordinates | input |
| int* | blo | g_b lower corner patch coordinates | input |
| int* | bhi | g_b upper corner patch coordinates | input |
| int* | clo | g_c lower corner patch coordinates | input |
| int* | chi | g_c upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise quotient of the two patches which must be of the same types and same number of elements. For two-dimensional arrays,
c(i,j) = a(i,j)/b(i,j)
The result (c) may replace one of the input arrays (a/b).
void GlobalArray::elemMaximum(const GlobalArray * g_a,
const GlobalArray * g_b) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | global array | input |
| const GlobalArray* | g_b | global array | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise maximum of the two arrays which must be of the same types and same number of elements. For two dimensional arrays,
c(i,j) = max{a(i,j), b(i,j)}
The result (c) may replace one of the input arrays (a/b).
void GlobalArray::elemMaximumPatch(
const GlobalArray * g_a, int *alo, int *ahi,
const GlobalArray * g_b, int *blo, int *bhi,
int *clo, int *chi) const
void GlobalArray::elemMaximumPatch(
const GlobalArray * g_a, int64_t *alo, int64_t *ahi,
const GlobalArray * g_b, int64_t *blo, int64_t *bhi,
int64_t *clo, int64_t *chi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | global array | input |
| const GlobalArray* | g_b | global array | input |
| int* | alo | g_a lower corner patch coordinates | input |
| int* | ahi | g_a upper corner patch coordinates | input |
| int* | blo | g_b lower corner patch coordinates | input |
| int* | bhi | g_b upper corner patch coordinates | input |
| int* | clo | g_c lower corner patch coordinates | input |
| int* | chi | g_c upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise maximum of the two patches which must be of the same types and same number of elements. For two-dimensional noncomplex arrays,
c(i,j) = max{a(i,j), b(i,j)}
If the data type is complex, then
c(i,j).real = max{ |a(i,j)|, |b(i,j)| } while c(i,j).image = 0.
The result (c) may replace one of the input arrays (a/b).
void GlobalArray::elemMinimum(const GlobalArray * g_a,
const GlobalArray * g_b) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | global array | input |
| const GlobalArray* | g_b | global array | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise minimum of the two arrays which must be of the same types and same number of elements. For two dimensional arrays,
c(i,j) = min{a(i,j), b(i,j)}
The result (c) may replace one of the input arrays (a/b).
void GlobalArray::elemMinimumPatch(
const GlobalArray * g_a, int *alo, int *ahi,
const GlobalArray * g_b, int *blo, int *bhi,
int *clo, int *chi) const
void GlobalArray::elemMinimumPatch(
const GlobalArray * g_a, int64_t *alo, int64_t *ahi,
const GlobalArray * g_b, int64_t *blo, int64_t *bhi,
int64_t *clo, int64_t *chi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | global array | input |
| int | g_b | global array | input |
| int* | alo | g_a lower corner patch coordinates | input |
| int* | ahi | g_a upper corner patch coordinates | input |
| int* | blo | g_b lower corner patch coordinates | input |
| int* | bhi | g_b upper corner patch coordinates | input |
| int* | clo | g_c lower corner patch coordinates | input |
| int* | chi | g_c upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise minimum of the two patches which must be of the same types and same number of elements. For two-dimensional of noncomplex arrays,
c(i,j) = min{a(i,j), b(i,j)}
If the data type is complex, then
c(i,j).real = min{ |a(i,j)|, |b(i,j)| } while c(i,j).image = 0.
The result (c) may replace one of the input arrays (a/b).
void GlobalArray::elemMultiply(const GlobalArray * g_a,
const GlobalArray * g_b) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | GlobalArray | input |
| const GlobalArray* | g_b | GlobalArray | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise product of the two arrays which must be of the same types and same number of elements. For two-dimensional arrays,
c(i, j) = a(i,j)*b(i,j)
The result (c) may replace one of the input arrays (a/b).
void GlobalArray::elemMultiplyPatch(
const GlobalArray * g_a, int *alo, int *ahi,
const GlobalArray * g_b, int *blo, int *bhi,
int *clo, int *chi) const
void GlobalArray::elemMultiplyPatch(
const GlobalArray * g_a, int64_t *alo, int64_t *ahi,
const GlobalArray * g_b, int64_t *blo, int64_t *bhi,
int64_t *clo, int64_t *chi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | global array | input |
| int | g_b | global array | input |
| int* | alo | g_a lower corner patch coordinates | input |
| int* | ahi | g_a upper corner patch coordinates | input |
| int* | blo | g_b lower corner patch coordinates | input |
| int* | bhi | g_b upper corner patch coordinates | input |
| int* | clo | g_c lower corner patch coordinates | input |
| int* | chi | g_c upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Computes the element-wise product of the two patches which must be of the same types and same number of elements. For two-dimensional arrays,
c(i,j) = a(i,j)*b(i,j)
The result (c) may replace one of the input arrays (a/b).
GAServices::error(const char *message, int code)
| Type | Name | Description | Intent |
|---|---|---|---|
| char* | message | string to print | input |
| int | code | code to print | input |
Local operation.
To be called in case of an error. Print an error message and an integer value that represents an error code as well as releasing some system resources. This is the required way of aborting the program execution.
GAServices::fence()
One-sided (non-collective).
Blocks the calling process until all the data transfers corresponding to GA operations called after ga_init_fence complete. For example, since ga_put might return before the data reaches the final destination, ga_init_fence and ga_fence allow the process to wait until the data tranfer is fully completed:
ga_init_fence();
ga_put(g_a, ...);
ga_fence();
ga_fence must be called after ga_init_fence. A barrier, ga_sync, assures the completion of all data transfers and implicitly cancels all outstanding ga_init_fence calls. ga_init_fence and ga_fence must be used in pairs, multiple calls to ga_fence require the same number of corresponding ga_init_fence calls. ga_init_fence/ga_fence pairs can be nested.
ga_fence works for multiple GA operations. For example:
ga_init_fence();
ga_put(g_a, ...);
ga_scatter(g_a, ...);
ga_put(g_b, ...);
ga_fence();
The calling process will be blocked until data movements initiated by two calls to ga_put and one ga_scatter complete.
void GlobalArray::fill(void *value) const
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | value | pointer to the value of appropriate type (double/double complex/long) that matches array type. | input |
Collective on the processor group inferred from the arguments.
Assign a single value to all elements in the array.
void GlobalArray::fillPatch (int lo[], int hi[], void *val) const
void GlobalArray::fillPatch (int64_t lo[], int64_t hi[], void *val) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo | patch of this GlobalArray | input |
| int* | hi | patch of this GlobalArray | input |
| void* | val | value to fill | input |
Collective on the processor group inferred from the arguments.
Fill the patch of g_a with value of `val'
void GlobalArray::freeGatscatBuf()
Local operation.
This function is used to free up internal buffers that were set with the corresponding allocation call. The buffers can be used to improve performance if multiple calls are being made to the gather/scatter operations.
void GlobalArray::gather(void *v, int * subsarray[], int n) const
void GlobalArray::gather(void *v, int64_t * subsarray[], int64_t n) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | n | number of elements | input |
| void* | v[n] | array containing values | input |
| int** | subsarray[n][ndim] | array of subscripts for each element | input |
One-sided (non-collective).
Gathers array elements from a global array into a local array. The contents of the input arrays (v, subsArray) are preserved.
for (k=0; k<= n; k++)
{v[k] = a[subsArray[k][0]][subsArray[k][1]][subsArray[k][2]]...;}
void GlobalArray::dgemm(char ta, char tb, int m, int n, int k,
double alpha, const GlobalArray *g_a, const
GlobalArray *g_b, double beta) const
void GlobalArray::dgemm(char ta, char tb, int64_t m, int64_t n, int64_t k,
double alpha, const GlobalArray *g_a, const
GlobalArray *g_b, double beta) const
| Type | Name | Description | Intent |
|---|---|---|---|
| char | ta | transpose operators | input |
| char | tb | transpose operators | input |
| int | m | number of rows of op(A) and of matrix C | input |
| int | n | number of columns of op(B) and of matrix C | input |
| int | k | number of columns of op(A) and rows of matrix op(B) | input |
| alpha | scale factor | input | |
| int | g_a | input array | input |
| int | g_b | input array | input |
| beta | scale factor | input |
Collective on the processor group inferred from the arguments.
Performs one of the matrix-matrix operations:
C := alpha*op( A )*op( B ) + beta*C,
where op( X ) is one of
op( X ) = X or op( X ) = X',
alpha and beta are scalars, and A, B, and C are matrices, with op( A ) an m by k matrix, op( B ) a k by n matrix and C an m by n matrix.
On entry, transa specifies the form of op( A ) to be used in the matrix multiplication as follows:
ta = `N' or `n', op( A ) = A.
ta = `T' or `t', op( A ) = A'.
One-sided (non-collective).
Copies data from global array section to the local array buffer. The local array is assumed to be have the same number of dimensions as the global array. Any detected inconsistencies or errors in the input arguments are fatal.
Example: For the ga_get operation transfering data from the [10:14, 0:4] section of 2-dimensional 15x10 global array into a local buffer 5x10 array we have:
lo={10,0,} hi={14,4}, ld={10}
Figure "get" below shows the GET operation.
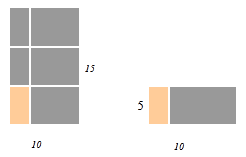
Return: The local array buffer.
void GlobalArray::getBlockInfo(int num_blocks[], int block_dims[])
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | num_blocks[ndim] | array containing number of blocks along each coordinate direction | output |
| int* | block_dims[ndim] | array containing block dimensions | output |
Local operation.
This subroutine returns information about the block-cyclic distribution associated with global array g_a. The number of blocks along each of the array axes are returned in the array num_blocks and the dimensions of the individual blocks, specified in the GA_Set_block_cyclic or GA_Set_block_cyclic_proc_grid subroutines, are returned in block_dims.
This is a local function.
int GlobalArray::getDebug()
Local operation.
This function returns the value of an internal flag in the GA library whose value can be set using the GA_Set_debug subroutine.
void GlobalArray::getDiagonal(const GlobalArray * g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | global array containing diagonal elements | input |
Collective on the processor group inferred from the arguments.
Inserts the diagonal elements of this matrix g_a into the vector g_v.
One-sided (non-collective).
This operation behaves similarly to the GA Get operation and will default to a standard Get if the global array has no ghost cells or the request does not fit into the ghost cell region of the calling processor. It is easier to use than the NGA_Access_ghosts function but it may be slower and requires more memory. The operation will copy data from the locally held portions of the global array, including the ghost cells, if the requested block falls within the region defined by visible block held by the process plus the ghost cell region. For example, if the process holds the visible block [2:8, 2:8] with a ghost cell width that is one element deep, then a request for the block [1:9,1:9] will use the local ghost cells to fill the local buffer. In this case, the data transfer is completely local. If the request is for a block such as [1:10,1:10], which would require data from another process, then the NGA_Get_ghost_block call reverts to an ordinary NGA_Get operation and ignores the locally held ghost data.
Return: The local array buffer.
void GAServices::dgop(double x[], int n, char *op);
void GAServices::igop(int x[], int n, char *op);
void GAServices::lgop(long x[], int n, char *op);
void GAServices::gop(int x[], int n, char *op);
void GAServices::gop(long x[], int n, char *op);
void GAServices::gop(float x[], int n, char *op);
void GAServices::gop(double x[], int n, char *op);
| Type | Name | Description | Intent |
|---|---|---|---|
| double | x[n] | array of elements | input/output |
| int | x[n] | array of elements | input/output |
| long | x[n] | array of elements | input/output |
| ing | x[n] | array of elements | input/output |
| long | x[n] | array of elements | input/output |
| float | x[n] | array of elements | input/output |
| double | x[n] | array of elements | input/output |
| int | n | number of elements | input |
| char | op | operator | input |
Collective on the world processor group.
Global OPeration.
X(1:N) is a vector present on each process. GOP `sums' elements of X accross all nodes using the commutative operator OP. The result is broadcast to all nodes. Supported operations include `+', `*', `max', `min', `absmax', `absmin'. The use of lowerecase for operators is necessary.
This operation is provided only for convenience purposes: it is available regardless of the message-passing library that GA is running with.
int GlobalArray::hasGhosts() const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | 1 if array has ghost cells | output |
Collective on the processor group inferred from the arguments.
This function returns 1 if the global array has some dimensions for which the ghost cell width is greater than zero, it returns 0 otherwise.
GAServices::initFence()
Local operation.
Initializes tracing of the completion status of data movement operations.
void GA::Initialize(int argc, char *argv[], size_t limit=0)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | argc | number of command line arguments | input |
| char** | argv | command line arguments | input |
| size_t | limit | amount of memory in bytes per process | input |
Collective on the processor group inferred from the arguments.
Allocate and initialize internal data structures in Global Arrays.
void GA::Initialize(int argc, char *argv[], unsigned long heapSize,
unsigned long stackSize, int type, size_t limit=0)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | argc | number of command line arguments | input |
| char** | argv | command line arguments | input |
| size_t | limit | amount of memory in bytes per process | input |
| unsigned long | heapSize | all of the dynamically allocated local memory | input |
| unsigned long | stackSize | all of the dynamically allocated local memory | input |
| int | type | data type | input |
Collective on the processor group inferred from the arguments.
Allocate and initialize internal data structures and set the limit for memory used in Global Arrays. The limit is per process: it is the amount of memory that the given processor can contribute to collective allocation of Global Arrays. It does not include temporary storage that GA might be allocating (and releasing) during execution of a particular operation.
*limit < 0 means "allow unlimited memory usage" in which case this operation is equivalent to GA_initialize.
void GlobalArray::inquire(int *type, int *ndim, int dims[]) const
void GlobalArray::inquire(int *type, int *ndim, int64_t dims[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | type | data type | output |
| int* | ndim | number of dimensions | output |
| int* | dims | array of dimensions | output |
Local operation.
Returns data type and dimensions of the array.
size_t GAServices::inquireMemory()
Returns the amount of memory (in bytes) used in the allocated global arrays on the calling processor.
char* GlobalArray::inquireName() const
Local operation.
Returns the name of an array represented by the handle g_a.
int GlobalArray::isMirrored()
Local operation.
This subroutine checks if the array is a mirrored array or not. Returns 1 if it is a mirrored array, else it returns 0.
int GlobalArray::lltSolve(const GlobalArray * g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | coefficient matrix | input |
Collective on the processor group inferred from the arguments.
Solves a system of linear equations
A * X = B
using the Cholesky factorization of an NxN double precision symmetric positive definite matrix A (represented by handle g_a). On successful exit B will contain the solution X.
It returns:
= 0 : successful exit
> 0 : the leading minor of this order is not positive
definite and the factorization could
not be completed.
int GlobalArray::locate(int subscript[]) const
int GlobalArray::locate(int64_t subscript[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | subscript[ndim] | element subscript | input |
| int | process ID owning the element at subscript | output |
Local operation.
Return the GA compute process ID that 'owns' the data. If any element of subscript[] is out of bounds "-1" is returned.
int GlobalArray::locateRegion(int lo[], int hi[], int map[], int procs[]) const;
int GlobalArray::locateRegion(int64_t lo[], int64_t hi[], int64_t map[], int procs[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for array section | input |
| int* | hi[ndim] | array of ending indices for array section | input |
| int* | map[] | array with mapping information | output |
| int* | procs[nproc] | list of processes that own a part of selection | output |
Local operation.
Return a list of the GA processes ID that `own' the data. Parts of the specified patch might be actually `owned' by several processes. If lo/hi are out of bounds "0" is returned, otherwise the return value is equal to the number of processes that hold the data.
map[n*2*ndim+i] - lo[i] for block n
map[n*2*ndim+ndim+i] - hi[i] for block n
procs[n] - processor id that owns data in patch
described by lo,hi
GAServices::lock(int mutex)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | mutex | mutex object id | input |
One-sided (non-collective).
Locks a mutex object identified by the mutex number. It is a fatal error for a process to attempt to lock a mutex which was already locked by this process.
void GlobalArray::luSolve(char trans, const GlobalArray * g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| trans | transpose or not transpose | input | |
| g_a | coefficient matrix | input |
Collective on the processor group inferred from the arguments.
Solve the system of linear equations op(A)X = B based on the LU factorization.
op(A) = A or A' depending on the parameter trans:
trans = `N' or `n' means that the transpose operator should not be applied.
trans = `T' or `t' means that the transpose operator should be applied.
Matrix A is a general real matrix. Matrix B contains possibly multiple rhs vectors. The array associated with the handle g_b is overwritten by the solution matrix X.
void GAServices::maskSync(int first, int last)
void GA::maskSync(int first, int last)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | first | masks the sync at the begining of the collective call | input |
| int | last | masks the sync at the end of the collective call | input |
Collective on the default processor group.
This subroutine can be used to remove synchronization calls from around collective operations. Setting the parameter first = .false. removes the synchronization prior to the collective operation, setting last = .false. removes the synchronization call after the collective operation. This call is applicable to all collective operations. It most be invoked before each collective operation.
void GlobalArray::matmulPatch(char transa, char transb,
void* alpha, void *beta, const GlobalArray *g_a,
int ailo, int aihi, int ajlo, int ajhi,
const GlobalArray *g_b, int bilo, int bihi,
int bjlo, int bjhi, int cilo, int cihi,
int cjlo, int cjhi) const;
void GlobalArray::matmulPatch(char transa, char transb,
void* alpha, void *beta, const GlobalArray *g_a,
int64_t ailo, int64_t aihi, int64_t ajlo,
int64_t ajhi, const GlobalArray *g_b, int64_t
bilo, int64_t bihi, int64_t bjlo, int64_t bjhi,
int64_t cilo, int64_t cihi, int64_t cjlo,
int64_t cjhi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| char | transa | transpose operators | input |
| char | transb | transpose operators | input |
| int | g_a | global array | input |
| int | g_b | global array | input |
| int | ailo | patch of g_a | input |
| int | aihi | patch of g_a | input |
| int | ajlo | patch of g_a | input |
| int | ajhi | patch of g_a | input |
| int | bilo | patch of g_b | input |
| int | bihi | patch of g_b | input |
| int | bjlo | patch of g_b | input |
| int | bjhi | patch of g_b | input |
| int | cilo | patch of g_c | input |
| int | cihi | patch of g_c | input |
| int | cjlo | patch of g_c | input |
| int | cjhi | patch of g_c | input |
| void* | alpha | scale factors | input |
| void* | beta | scale factors | input |
void GlobalArray::matmulPatch(char transa, char transb, void* alpha,
void *beta,const GlobalArray *g_a,
int *alo, int *ahi, const GlobalArray *g_b,
int *blo, int *bhi, int *clo, int *chi) const
void GlobalArray::matmulPatch(char transa, char transb, void* alpha,
void *beta, const GlobalArray *g_a,
int64_t *alo, int64_t *ahi, const GlobalArray
*g_b, int64_t *blo, int64_t *bhi,
int64_t *clo, int64_t *chi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | global array | input |
| int | g_b | global array | input |
| int* | alo | array of patch of g_a | input |
| int* | ahi | array of patch of g_a | input |
| int* | blo | array of patch of g_b | input |
| int* | bhi | array of patch of g_b | input |
| int* | clo | array of patch of g_c | input |
| int* | chi | array of patch of g_c | input |
| void* | alpha | scale factors | input |
| void* | beta | scale factors | input |
| char | transa | transpose operators | input |
| char | transb | transpose operators | input |
Collective on the processor group inferred from the arguments.
ga_matmul_patch is a patch version of ga_dgemm and comes in 2-D and N-D versions. The 2-D interface performs the operation:
C[cilo:cihi,cjlo:cjhi] := alpha* AA[ailo:aihi,ajlo:ajhi] *
BB[bilo:bihi,bjlo:bjhi] ) +
beta*C[cilo:cihi,cjlo:cjhi],
where AA = op(A), BB = op(B), and op(X) is one of
op(X) = X or op(X) = X',
Valid values for transpose arguments: 'n', 'N', 't', 'T'. It works for both double and double complex data tape.
nga_matmul_patch is a N-dimensional patch version of ga_dgemm and is similar to the 2-D interface:
C[clo[]:chi[]] := alpha* AA[alo[]:ahi[]] *
BB[blo[]:bhi[]] ) + beta*C[clo[]:chi[]],
void GlobalArray::median(const GlobalArray * g_a,
const GlobalArray * g_b,
const GlobalArray * g_c) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | global array | input |
| const GlobalArray* | g_b | global array | input |
| const GlobalArray* | g_c | global array | input |
Collective on the processor group inferred from the arguments.
Computes the componentwise Median of three arrays g_a, g_b, and g_c, and stores the result in this array g_m. The result (m) may replace one of the input arrays (a/b/c).
void GlobalArray::medianPatch(
const GlobalArray *g_a, int *alo, int *ahi,
const GlobalArray *g_b, int *blo, int *bhi,
const GlobalArray *g_c, int *clo, int *chi,
int *mlo, int *mhi) const;
void GlobalArray::medianPatch(
const GlobalArray *g_a, int64_t *alo, int64_t *ahi,
const GlobalArray *g_b, int64_t *blo, int64_t *bhi,
const GlobalArray *g_c, int64_t *clo, int64_t *chi,
int64_t *mlo, int64_t *mhi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | global array | input |
| int | g_b | global array | input |
| int | g_c | global array | input |
| int* | alo | g_a lower corner patch coordinates | input |
| int* | ahi | g_a upper corner patch coordinates | input |
| int* | blo | g_b lower corner patch coordinates | input |
| int* | bhi | g_b upper corner patch coordinates | input |
| int* | clo | g_c lower corner patch coordinates | input |
| int* | chi | g_c upper corner patch coordinates | input |
| int* | mlo | g_m lower corner patch coordinates | input |
| int* | mhi | g_m upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Computes the componentwise Median of three patches g_a, g_b, and g_c, and stores the result in this patch g_m. The result (m) may replace one of the input patches (a/b/c).
int GAServices::memoryAvailable() ;
Local operation.
Returns amount of memory (in bytes) left for allocation of new global arrays on the calling processor.
Note: If GA_uses_ma returns true, then GA_Memory_avail returns the lesser of the amount available under the GA limit and the amount available from MA (according to ma_inquire_avail operation). If no GA limit has been set, it returns what MA says is available.
If ( !GA_Uses_ma() && !GA_Memory_limited() ) returns < 0, indicating that the bound on currently available memory cannot be determined.
int GAServices::memoryLimited()
Local operation.
Indicates if limit is set on memory usage in Global Arrays on the calling processor. "1" means "yes", "0" means "no".
Returns: True for "yes", False for "no"
void GlobalArray::mergeDistrPatch(
int alo[], int ahi[], GlobalArray *g_a,
int blo[], int bhi[])
void GlobalArray::mergeDistrPatch(
int64_t alo[], int64_t ahi[], GlobalArray *g_a,
int64_t blo[], int64_t bhi[])
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | alo[ndim] | patch indices of mirrored array | input |
| int* | ahi[ndim] | patch indices of mirrored array | input |
| int* | blo[ndim] | patch indices of result array | input |
| int* | bhi[ndim] | patch indices of result array | input |
| GlobalArray* | g_a | global array containing result | input |
Collective on the processor group inferred from the arguments.
This function merges all copies of a patch of a mirrored array (g_a) into a patch in a distributed array (g_b).
void GlobalArray::mergeMirrored()
Collective on the processor group inferred from the arguments.
This subroutine merges mirrored arrays by adding the contents of each array across nodes. The result is that each mirrored copy of the array represented by g_a is the sum of the individual arrays before the merge operation. After the merge, all mirrored arrays are equal.
void GlobalArray::nbAcc(int lo[], int hi[],
void *buf, int ld[], void *alpha, GANbhdl *nbhandle)
void GlobalArray::nbAcc(int64_t lo[], int64_t hi[],
void *buf, int64_t ld[], void *alpha, GANbhdl *nbhandle)
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | patch coordinates of block | input |
| int* | hi[ndim] | patch coordinates of block | input |
| void* | buf | local buffer to receive data | input |
| int* | ld[ndim-1] | array of strides for local data | input |
| void* | alpha | multiplier for data before adding to existing results | input |
| GANbhdl* | nbhandle | nonblocking handle | output |
One-sided (non-collective).
A non-blocking version of the blocking accumulate operation. The accumulate operation can be completed locally by making a call to the wait (e.g., NGA_NbWait) routine.
Non-blocking version of ga.acc.
The accumulate operation can be completed locally by making a call to the ga.nbwait() routine.
Combines data from buffer with data in the global array patch.
The buffer array is assumed to be have the same number of dimensions as the global array. If the buffer is not contiguous, a contiguous copy will be made.
global array section (lo[],hi[]) += alpha * buffer
void GlobalArray::nbGet(int lo[], int hi[],
void *buf, int ld[], GANbhdl *nbhandle)
void GlobalArray::nbGet(int64_t lo[], int64_t hi[],
void *buf, int64_t ld[], GANbhdl *nbhandle)
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | patch coordinates of block | input |
| int* | hi[ndim] | patch coordinates of block | input |
| void* | buf | local buffer to receive data | input/output |
| int* | ld[ndim-1] | array of strides for local data | input |
| GANbhdl* | nbhandle | nonblocking handle | output |
One-sided (non-collective).
A non-blocking version of the blocking get operation. The get operation can be completed locally by making a call to the wait (e.g., NGA_NbWait) routine.
Copies data from global array section to the local array buffer.
The local array is assumed to be have the same number of dimensions as the global array. Any detected inconsitencies/errors in the input arguments are fatal.
Returns: The local array buffer.
void GlobalArray::nblock(int nblock[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | nblock[ndim] | number of partitions for each dimension | output |
Local operation.
Given a distribution of an array represented by the handle g_a, returns the number of partitions of each array dimension.
void GlobalArray::nbPut(int lo[], int hi[],
void *buf, int ld[], GANbhdl *nbhandle)
void GlobalArray::nbPut(int64_t lo[], int64_t hi[],
void *buf, int64_t ld[], GANbhdl *nbhandle)
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | patch coordinates of block | input |
| int* | hi[ndim] | patch coordinates of block | input |
| void* | buf | local buffer to receive data | input |
| int* | ld[ndim-1] | array of strides for local data | input |
| GANbhdl* | nbhandle | nonblocking handle | output |
One-sided (non-collective).
A non-blocking version of the blocking put operation. The put operation can be completed locally by making a call to the wait (e.g., NGA_NbWait) routine.
Copies data from local array buffer to the global array section.
The local array is assumed to be have the same number of dimensions as the global array. Any detected inconsitencies/errors in input arguments are fatal.
int GAServices::nbTest(GANbhdl *nbhandle)
| Type | Name | Description | Intent |
|---|---|---|---|
| GANbhdl* | nbhandle | nonblocking handle | input |
| int | 1 if operation has completed | output |
One-sided (non-collective).
This function tests a non-blocking one-sided operation for completion. If true, the function is completed locally and the buffer is available for either use or reuse, depending on the operation. Once this operation has returned true, there is no need to call nbwait on the handle. The test function is properly implemented only on the Progress Ranks and RMA runtimes. For other runtimes, it defaults to the non-blocking wait function and always returns true.
void GAServices::nbWait(GANbhdl *nbhandle)
| Type | Name | Description | Intent |
|---|---|---|---|
| GANbhdl* | nbhandle | nonblocking handle | input |
One-sided (non-collective).
This function completes a non-blocking one-sided operation locally. Waiting on a nonblocking put or an accumulate operation assures that data was injected into the network and the user buffer can now be reused. Completing a get operation assures data has arrived into the user memory and is ready for use. The wait operation ensures only local completion. Not all runtimes support true non-blocking capability. For those that don't all operations are blocking and the wait function is a no-op.
Unlike their blocking counterparts, the nonblocking operations are not ordered with respect to the destination. Performance being one reason, the other reason is that ensuring ordering would incur additional and possibly unnecessary overhead on applications that do not require their operations to be ordered. For cases where ordering is necessary, it can be done by calling a fence operation. The fence operation is provided to the user to confirm remote completion if needed.
int GlobalArray::ndim() const
Local operation.
Returns the number of dimensions in the array represented by the handle g_a.
int GAServices::nodes()
Local operation.
Returns the number of the GA compute (user) processes.
int GAServices::nodeid()
Local operation.
Returns the GA process id (0, ..., ga_Nnodes()-1) of the requesting compute process.
void GlobalArray::normInfinity(double *nm) const
| Type | Name | Description | Intent |
|---|---|---|---|
| double* | nm | matrix/vector infinity-norm value | output |
Collective on the processor group inferred from the arguments.
Computes the infinity-norm of the matrix or vector g_a.
void GlobalArray::norm1(double *nm) const
| Type | Name | Description | Intent |
|---|---|---|---|
| double* | nm | matrix/vector 1-norm value | output |
Collective on the processor group inferred from the arguments.
Computes the 1-norm of the matrix or vector g_a.
int GlobalArray::overlay(const GlobalArray *g_p)
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_p | parent array | input |
Collective on the processor group inferred from the arguments.
The overlay function is designed to allow users to create a global array on top of an existing global array. This can be used in situations where it is desirable to create and destroy a large number of global arrays in rapid succession and where the size of these global arrays can be bounded beforehand. A large global array is created at the start using conventional create or allocate calls and then is used as the parent for new global arrays that are allocated using the overlay call. This approach removes some collectives and memory allocation and deallocation calls from the process of creating a global array and should result in improved performance. Note that the parent global array should not be used while another array is overlayed on top of it.
Collective on the processor group inferred from the arguments.
void GlobalArray::pack(const GlobalArray *g_dest,
const GlobalArray *g_mask, int lo, int hi,
int *icount) const
void GlobalArray::pack(const GlobalArray *g_dest,
const GlobalArray *g_mask, int64_t lo, int64_t hi,
int64_t *icount) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_dest | destination array | input |
| const GlobalArray* | g_mask | mask array | input |
| int | lo | coordinate interval to pack | input |
| int | hi | coordinate interval to pack | input |
| int* | icount | number of packed elements | output |
Collective on the processor group inferred from the arguments.
The pack subroutine is designed to compress the values in the source vector g_src into a smaller destination array g_dest based on the values in an integer mask array g_mask. The values lo and hi denote the range of elements that should be compressed and icount is a variable that on output lists the number of values placed in the compressed array. This operation is the complement of the GA_Unpack operation. An example is shown below
GA_Pack(g_src, g_dest, g_mask, 1, n, &icount); g_mask: 1 0 0 0 0 0 1 0 1 0 0 1 0 0 1 1 0 g_src: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 g_dest: 1 7 9 12 15 16 icount: 6
The current implementation requires that the distribution of the g_mask array matches the distribution of the g_src array.
void GlobalArray::patchEnum(int lo, int hi, void *istart, void *inc)
void GlobalArray::patchEnum(int64_t lo, int64_t hi, void *start, void *inc)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | lo | coordinate interval to enumerate | input |
| int | hi | coordinate interval to enumerate | input |
| void* | istart | starting value of enumeration | input |
| void* | inc | increment value | input |
Collective on the processor group inferred from the arguments.
This subroutine enumerates the values of an array between elements lo and hi starting with the value start and incrementing each subsequent value by inc. This operation is only applicable to 1-dimensional arrays. An example of its use is shown below:
GA_Patch_enum(g_a, 1, n, 7, 2); g_a: 7 9 11 13 15 17 19 21 23 ...
void GlobalArray::periodicAcc(int lo[], int hi[], void* buf,
int ld[], void* alpha) const
void GlobalArray::periodicAcc(int64_t lo[], int64_t hi[], void* buf,
int64_t ld[], void* alpha) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for array section | input |
| int* | hi[ndim] | array of ending indices for array section | input |
| void* | buf | pointer to the local buffer array | input |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
| alpha | double/double complex/long scale factor | input |
One-sided (non-collective).
Same as nga_acc except the indices can extend beyond the array boundary/dimensions in which case the library wraps them around. For Python, this is the periodic version of ga.acc.
Combines data from buffer with data in the global array patch.
The buffer array is assumed to be have the same number of dimensions as the global array. If the buffer is not contiguous, a contiguous copy will be made.
global array section (lo[],hi[]) += alpha * buffer
void GlobalArray::periodicGet(int lo[], int hi[], void* buf, int ld[]) const
void GlobalArray::periodicGet(int64_t lo[], int64_t hi[], void* buf,
int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for global array section | input |
| int* | hi[ndim] | array of ending indices for global array section | input |
| void* | buf | pointer to the local buffer array where the data goes | output |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
One-sided (non-collective).
Same as nga_get except the indices can extend beyond the array boundary/dimensions in which case the library wraps them around.
The local array is assumed to be have the same number of dimensions as the global array. Any detected inconsitencies/errors in the input arguments are fatal.
Returns: The local Array buffer.
void GlobalArray::periodicPut(int lo[], int hi[], void* buf, int ld[]) const
void GlobalArray::periodicPut(int64_t lo[], int64_t hi[], void* buf, int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for global array section | input |
| int* | hi[ndim] | array of ending indices for global array section | input |
| void* | buf | pointer to the local buffer array where the data goes | input |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
One-sided (non-collective).
Same as nga_put except the indices can extend beyond the array boundary/dimensions in which case the library wraps them around. The indices can extend beyond the array boundary/dimensions in which case the libray wraps them around. Copies data from local array buffer to the global array section. The local array is assumed to be have the same number of dimensions as the global array. Any detected inconsitencies/errors in input arguments are fatal.
void PGroup::brdcst(void* buf, int lenbuf, int root)
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | buf | pointer to buffer containing data | input/output |
| int | lenbuf | length of data (in bytes) | input |
| int | root | processor sending message | input |
Collective on the processor group inferred from the arguments.
Broadcast data from processor specified by root to all other processors in the processor group specified by p_handle. The length of the message in bytes is specified by lenbuf. The initial and broadcasted data can be found in the buffer specified by the pointer buf.
If the buffer is not contiguous, an error is raised. This operation is provided only for convenience purposes: it is available regardless of the message-passing library that GA is running with.
Returns: The buffer in case a temporary was passed in.
PGroup::PGroup(int *plist, int size)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | size | number of processors in group | input |
| int* | plist[size] | list of processor IDs in group | input |
| PGroup | pgroup object | output |
Collective on the default processor group.
This command is used to create a processor group. At present, it must be invoked by all processors in the current default processor group. The list of processors use the indexing scheme of the default processor group. If the default processor group is the world group, then these indices are the usual processor indices. This function returns a process group handle that can be used to reference this group by other functions.
PGroup::~PGroup()
Collective on the processor group inferred from the arguments.
This command is used to free up a processor group handle. It returns 0 if the processor group handle was not previously active.
Pgroup PGroup::duplicate()
Return a copy of an existing processor group.
Collective on the processor group inferred from the arguments.
static PGroup* PGroup::getDefault()
Local operation.
This function will return a handle to the default processor group, which can then be used to create a global array using one of the NGA_create_*_config or GA_Set_pgroup calls.
static PGroup * PGroup::getMirror()
Local operation.
This function will return a handle to the mirrored processor group, which can then be used to create a global array using one of the NGA_create_*_config or GA_Set_pgroup calls.
static PGroup * PGroup::getWorld()
Local operation.
This function will return a handle to the world processor group, which can then be used to create a global array using one of the NGA_create_*_config or GA_Set_pgroup calls.
void PGroup::gop(float *buf, int n, char* op)
void PGroup::gop(double *buf, int n, char* op)
void PGroup::gop(int *buf, int n, char* op)
void PGroup::gop(long *buf, int n, char* op)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | n | number of elements | input |
| float* | x[n] | array of elements | input/output |
| double* | x[n] | array of elements | input/output |
| int* | x[n] | array of elements | input/output |
| long* | x[n] | array of elements | input/output |
| char* | op | operator | input |
Collective on the processor group inferred from the arguments.
The buf[n] is an array present on each processor in the processor group p_handle. The GA_Pgroup_dgop `sums' all elements in buf[n] across all processors in the group specified by p_handle using the commutative operation specified by the character string op. The result is broadcast to all processor in p_handle. Allowed strings are `+', `*', `max', `min', `absmax', `absmin'. The use of lowerecase for operators is necessary.
int PGroup::nodes()
Local operation.
This function returns the number of processors contained in the group specified by p_handle.
Returns the number of processors contained in the group specified by pgroup.
int PGroup::nodeid()
Local operation.
This function returns the relative index of the processor in the processor group specified by p_handle. This index will generally differ from the absolute processor index returned by GA_Nodeid if the processor group is not the world group.
Returns the relative index of the processor in the processor group specified by pgroup.
Pgroup PGroup::self()
Return a processor group that only contains the calling process.
One-sided (non-collective).
static void PGroup::setDefault(PGroup *p_handle)
| Type | Name | Description | Intent |
|---|---|---|---|
| PGroup* | p_handle | processor group | input |
Collective on the processor group inferred from the arguments.
This function can be used to reset the default processor group on a collection of processors. All processors in the group referenced by p_handle must make a call to this function. Any standard global array call that is made after resetting the default processor group will be restricted to processors in that group. Global arrays that are created after resetting the default processor group will only be defined on that group and global operations, such as GA_Sync or GA_Igop, and will be restricted to processors in that group. The GA_Pgroup_set_default call can be used to rapidly convert large applications, written with GA, into routines that run on processor groups.
The default processor group can be overridden by using GA calls that require an explicit group handle as one of the arguments.
void PGroup::sync()
Collective on the processor group inferred from the arguments.
This operation executes a synchronization group across the processors in the processor group specified by p_handle. Nodes outside this group are unaffected.
void GlobalArray::print() const
Collective on the processor group inferred from the arguments.
Prints an entire array to the standard output.
void GlobalArray::printDistribution() const
Collective on the processor group inferred from the arguments.
Prints the array distribution.
void GlobalArray::printFile(FILE *file) const
| Type | Name | Description | Intent |
|---|---|---|---|
| file | file pointer | input |
Collective on the processor group inferred from the arguments.
Prints an entire array to a file.
void GlobalArray::printPatch(int* lo, int* hi, int pretty) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo | low coordinates of the patch | input |
| int* | hi | high coordinates of the patch | input |
| int | pretty | formatting flag | input |
Collective on the processor group inferred from the arguments.
Prints a patch of g_a array to the standard output. If the variable pretty has the value 0 then output is printed in a dense fashion. If pretty has the value 1 then output is formatted and rows/columns are labeled.
void GAServices::printStats()
Local operation.
This non-collective (MIMD) operation prints information about:
void GlobalArray::procTopology(int proc, int coord[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | proc | process id | input |
| int* | coord[ndim] | coordinates in processor grid | output |
Local operation.
Based on the distribution of an array associated with handle g_a, determines coordinates of the specified processor in the virtual processor grid corresponding to the distribution of array g_a. The numbering starts from 0. The values of -1 means that the processor doesn't "own" any section of the array represented by g_a.
void GlobalArray::put(int lo[], int hi[], void *buf, int ld[]) const
void GlobalArray::put(int64_t lo[], int64_t hi[], void *buf,
int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for global array section | input |
| int* | hi[ndim] | array of ending indices for global array section | input |
| void* | buf | pointer to the local buffer array where the data is | input |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
One-sided (non-collective).
Copies data from the local array buffer to the global array section. The local array is assumed to have the same number of dimensions as the global array. Any detected inconsistencies or errors in input arguments are fatal.
long GlobalArray::readInc(int subscript[], long inc)
long GlobalArray::readInc(int64_t subscript[], long inc)
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | subscript[ndim] | subscript array for the referenced element | input |
| long | inc | amount element is incremented after read | input |
One-sided (non-collective).
Atomically read and increment an element in an integer array.
*BEGIN CRITICAL SECTION* old_value = a(subscript) a(subscript) += inc *END CRITICAL SECTION* return old_value
void GlobalArray::recip() const
Collective on the processor group inferred from the arguments.
Take the element-wise reciprocal of the array.
void GlobalArray::recipPatch(int *lo, int *hi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo | lower corner patch coordinates | input |
| int* | hi | upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Take element-wise reciprocal of the patch.
void GlobalArray::release(int lo[], int hi[]) const
void GlobalArray::release(int64_t lo[], int64_t hi[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for array section | input |
| int* | hi[ndim] | array of ending indices for array section | input |
Local operation.
Releases access to a global array when the data was read only.
Your code should look like:
NGA_Distribution(g_a, myproc, lo,hi);
NGA_Access(g_a, lo, hi, \&ptr, ld);
GA_Release(g_a, lo, hi);
NOTE: see restrictions specified for ga_access.
void GlobalArray::releaseBlock(int index) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | index | block index | input |
Local operation.
Releases access to the block of data specified by the integer index when data was accessed as read only. This is only applicable to block-cyclic data distributions created using the simple block-cyclic distribution.
void GlobalArray::releaseBlockGrid(int index[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | index[ndim] | indices of block in array | input |
Local operation.
Releases access to the block of data specified by the subscript array when data was accessed as read only. This is only applicable to block-cyclic data distributions created using the SCALAPACK data distribution.
void GlobalArray::releaseBlockSegment(int proc) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | proc | process ID/rank | input |
Local operation.
Releases access to the block of locally held data for a block-cyclic array, when data was accessed as read-only.
void GlobalArray::releaseGhostElement(int subscript[]) const
void GlobalArray::releaseGhostElement(int64_t subscript[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | subscript[ndim] | indices of element | input |
Local operation.
Releases access to the locally held data for an array with ghost elements, when data was accessed as read-only.
void GlobalArray::releaseGhosts() const
Local operation.
Releases access to the locally held block of data containing ghost elements, when data was accessed as read-only.
void GlobalArray::releaseUpdate(int lo[], int hi[]) const
void GlobalArray::releaseUpdate(int64_t lo[], int64_t hi[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for array section | input |
| int* | hi[ndim] | array of ending indices for array section | input |
Local operation.
Releases access to the data. It must be used if the data was accessed for writing.
NOTE: see restrictions specified for ga_access.
void GlobalArray::releaseUpdateBlock(int index) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | index | block index | input |
Local operation.
Releases access to the block of data specified by the integer index when data was accessed in read-write mode. This is only applicable to block-cyclic data distributions created using the simple block-cyclic distribution.
void GlobalArray::releaseUpdateBlockGrid(int index[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | index[ndim] | indices of block in array | input |
Local operation.
Releases access to the block of data specified by the subscript array when data was accessed in read-write mode. This is only applicable to block-cyclic data distributions created using the SCALAPACK data distribution.
void GlobalArray::releaseUpdateBlockSegment(int proc) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | proc | process ID/rank | input |
Local operation.
Releases access to the block of locally held data for a block-cyclic array, when data was accessed as read-only.
void GlobalArray::releaseUpdateGhostElement(int subscript[]) const
void GlobalArray::releaseUpdateGhostElement(int64_t subscript[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | subscript[ndim] | indices of element | input |
Local operation.
Releases access to the locally held data for an array with ghost elements, when data was accessed in read-write mode.
void GlobalArray::releaseUpdateGhosts() const
Local operation.
Releases access to the locally held block of data containing ghost elements, when data was accessed in read-write mode.
void GlobalArray::scale(void *value) const
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | value | pointer to the value of appropriate type | input |
Collective on the processor group inferred from the arguments.
Scales an array by the constant s. Note that the library is unable to detect errors when the pointed value is of a different type than the array.
void GlobalArray::scaleCols(const GlobalArray * g_v) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_v | global array containing scale factors | input |
Collective on the processor group inferred from the arguments.
Scales the columns of this matrix g_a using the vector g_v.
void GlobalArray::scalePatch (int lo[], int hi[], void *val) const;
void GlobalArray::scalePatch (int64_t lo[], int64_t hi[], void *val) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo | patch of this GlobalArray | input |
| int* | hi | patch of this GlobalArray | input |
| void* | val | scale factor | input |
Collective on the processor group inferred from the arguments.
Scale an array by the factor `val'
void GlobalArray::scaleRows(const GlobalArray * g_v) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_v | global array containing scale factors | input |
Collective on the processor group inferred from the arguments.
Scales the rows of this matrix g_a using the vector g_v.
void GlobalArray::scanAdd(const GlobalArray *g_dest, const GlobalArray *g_mask,
int lo, int hi, int excl) const
void GlobalArray::scanAdd(const GlobalArray *g_dest, const GlobalArray *g_mask,
int64_t lo, int64_t hi, int excl) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_dest | handle for destination array | input |
| int | g_mask | handle for integer array representing mask | input |
| int | lo | low and high values of range on which operation is performed | input |
| int | hi | low and high values of range on which operation is performed | input |
| int | excl | value to signify if masked values are included in in add | input |
Collective on the processor group inferred from the arguments.
This operation will add successive elements in a source vector g_src and put the results in a destination vector g_dest. The addition will restart based on the values of the integer mask vector g_mask. The scan is performed within the range specified by the integer values lo and hi. Note that this operation can only be applied to 1-dimensional arrays. The excl flag determines whether the sum starts with the value in the source vector corresponding to the location of a 1 in the mask vector (excl=0) or whether the first value is set equal to 0 (excl=1). Some examples of this operation are given below.
GA_Scan_add(g_src, g_dest, g_mask, 1, n, 0); g_mask: 1 0 0 0 0 0 1 0 1 0 0 1 0 0 1 1 0 g_src: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 g_dest: 1 3 6 10 16 21 7 15 9 19 30 12 25 39 15 16 33 GA_Scan_add(g_src, g_dest, g_mask, 1, n, 1); g_mask: 1 0 0 0 0 0 1 0 1 0 0 1 0 0 1 1 0 g_src: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 g_dest: 0 1 3 6 10 15 0 7 0 9 19 0 12 25 0 0 16
void GlobalArray::scanCopy(const GlobalArray *g_dest,
const GlobalArray *g_mask, int lo, int hi) const
void GlobalArray::scanCopy(const GlobalArray *g_dest,
const GlobalArray *g_mask, int64_t lo, int64_t hi) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_dest | handle for destination array | input |
| const GlobalArray* | g_mask | handle for integer array representing mask | input |
| int | lo | low values of range on which operation is performed | input |
| int | hi | high values of range on which operation is performed | input |
Collective on the processor group inferred from the arguments.
This subroutine does a segmented scan-copy of values in the source array g_src into a destination array g_dest with segments defined by values in the integer mask array g_mask. The scan-copy operation is only applied to the range between the lo and hi indices. This operation is restriced to 1-dimensional arrays. The resulting destination array will consist of segments of consecutive elements with the same value. An example is shown below.
GA_Scan_copy(g_src, g_dest, g_mask, 1, n); g_mask: 1 0 0 0 0 0 1 0 1 0 0 1 0 0 1 1 0 g_src: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 g_dest: 1 1 1 1 1 1 7 7 9 9 9 12 12 12 15 16 16
void GlobalArray::scatter(void *v, int *subsarray[], int n) const
void GlobalArray::scatter(void *v, int64_t *subsarray[], int64_t n) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | n | number of elements | input |
| void* | v[n] | array containing values | input |
| int** | subsarray[n][ndim] | array of subscripts for each element | input |
One-sided (non-collective).
Scatters array elements into a global array. The contents of the input arrays (v,subsArray) are preserved.
for (k=0; k<= n; k++)
{a[[subsArray[k][0]][subsArray[k][1]][subsArray[k][2]]... = v[k];}
void GlobalArray::scatterAcc(void *v, int *subsarray[], int n, void *alpha) const
void GlobalArray::scatterAcc(void *v, int64_t *subsarray[], int64_t n, void *alpha) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | n | number of elements | input |
| void* | v[n] | array containing values | input |
| int** | subsarray[n][ndim] | array of subscripts for each element | input |
| void* | alpha | multiplicative factor | input |
One-sided (non-collective).
Scatters array elements from a local array into a global array. Adds values from the local array to existing values in the global array after multiplying by alpha. The contents of the input arrays (v, subsArray) are preserved.
for (k=0; k<= n; k++)
{a[subsArray[k][0]][subsArray[k][1]][subsArray[k][2]]... += v[k];}
Like scatter, but adds values to existing values in the global array after multiplying by alpha.
void GlobalArray::selectElem(char *op, void* val, int index[]) const
void GlobalArray::selectElem(char *op, void* val, int64_t index[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| char* | op | operator (``min'',``max'') | input |
| void* | val | address where value should be stored | output |
| int* | index[ndim] | array index for the selected element | output |
Collective on the processor group inferred from the arguments.
Returns the value and index for an element that is selected by the specified operator ("min" or "max") in a global array corresponding to g_a handle.
void GlobalArray::setArrayName(char *name) const
| Type | Name | Description | Intent |
|---|---|---|---|
| char* | name | array name | input |
Collective on the processor group inferred from the arguments.
This function can be used to assign a unique character string name to a Global Array handle that was obtained using the GA_Create_handle function.
void GlobalArray::setBlockCyclic(int dims[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | dims | array of block dimensions | input |
Collective on the processor group inferred from the arguments.
This subroutine is used to create a global array with a simple block-cyclic data distribution. The array is broken up into blocks of size dims and each block is numbered sequentially using a column major indexing scheme. The blocks are then assigned in a simple round-robin fashion to processors.
Figure "stblkcy" below illustrates an array containing 25 blocks distributed on 4 processors.
Blocks at the edge of the array may be smaller than the block size specified in dims. In the example below, blocks 4, 9, 14, 19, 20, 21, 22, 23, and 24 might be smaller than the remaining blocks. Most global array operations are insensitive to whether or not a block-cyclic data distribution is used, although performance may be slower in some cases if the global array is using a block-cyclic data distribution. Individual data blocks can be accessesed using the block-cyclic access functions.
void GlobalArray::setBlockCyclicProcGrid(int dims[], int proc_grid[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | dims | array of block dimensions | input |
| int* | proc_grid | processor grid dimensions | input |
Collective on the processor group inferred from the arguments.
This subroutine is used to create a global array with a SCALAPACK-type block cyclic data distribution. The user specifies the dimensions of the processor grid in the array proc_grid. The product of the processor grid dimensions must equal the number of total number of processors and the number of dimensions in the processor grid must be the same as the number of dimensions in the global array. The data blocks are mapped onto the processor grid in a cyclic manner along each of the processor grid axes.
Figure "setblkcyprocgrid" below illustrates an array consisting of 25 data blocks distributed on 6 processors.
The 6 processors are configured in a 3 by 2 processor grid. Blocks at the edge of the array may be smaller than the block size specified in dims. Most global array operations are insensitive to whether or not a block-cyclic data distribution is used, although performance may be slower in some cases if the global array is using a block-cyclic data distribution. Individual data blocks can be accessesed using the block-cyclic access functions.
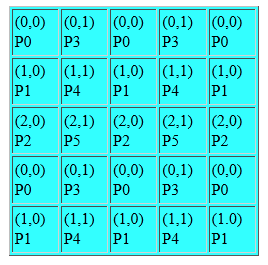
void GlobalArray::setChunk(int chunk[]) const
void GlobalArray::setChunk(int64_t chunk[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | chunk | array of chunk widths | input |
Collective on the processor group inferred from the arguments.
This function is used to set the chunk array for a global array handle that was obtained using the GA_Create_handle function. The chunk array is used to determine the minimum number of array elements assigned to each processor along each coordinate direction.
void GlobalArray::setData(int ndim, int dims[], int type) const
void GlobalArray::setData(int ndim, int64_t dims[], int type) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | ndim | dimension of global array | input |
| int* | dims | dimensions of global array | input |
| int | type | data type of global array | input |
Collective on the processor group inferred from the arguments.
This function can be used to set the array dimension, the coordinate dimensions, and the data type assigned to a Global Array handle obtained using the GA_Create_handle function.
void GAServices::setDebug(int dbg);
| Type | Name | Description | Intent |
|---|---|---|---|
| dbg | value to set internal flag | input |
Local operation.
This function sets an internal flag in the GA library to either true or false. The value of this flag can be recovered at any time using the GA_Get_debug function. The flag is set to false when the the GA library is initialized. This can be useful in a number of debugging situations, especially when examining the behavior of routines that are called in multiple locations in a code.
void GlobalArray::setDiagonal(const GlobalArray * g_v) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_v | global array containing diagonal values | input |
Collective on the processor group inferred from the arguments.
Sets the diagonal elements of this matrix g_a with the elements of the vector g_v.
void GlobalArray::setGhosts(int width[]) const
void GlobalArray::setGhosts(int64_t width[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| width[ndim] | array of ghost cell widths | input |
Collective on the processor group inferred from the arguments.
This function can be used to set the ghost cell widths for a global array handle that was obtained using the GA_Create_handle function. The ghosts cells widths indicate how many ghost cells are used to pad the locally held array data along each dimension. The padding can be set independently for each coordinate dimension.
void GlobalArray::setIrregDistr(int mapc[], int nblock[]) const
void GlobalArray::setIrregDistr(int64_t mapc[], int64_t nblock[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| mapc[s] | starting index for each block; the size s is the sum of all elements of the array nblock | input | |
| nblock[ndim] | number of blocks that each dimension is divided into | input |
Collective on the processor group inferred from the arguments.
This function can be used to partition the array data among the individual processors for a global array handle obtained using the GA_Create_handle function.
The distribution is specified as a Cartesian product of distributions for each dimension. For example, the following figure demonstrates the distribution of a 2-dimensional array 8x10 on 6 processors. nblock(2)={3,2}, the size of mapc array is s=5 and array mapc contains the following elements mapc={0,2,6,0,5}. The distribution is nonuniform because, P1 and P4 get 20 elements each and processors P0, P2, P3, and P5 only 10 elements each.
The array width() is used to control the width of the ghost cell boundary around the visible data on each processor. The local data of the global array residing on each processor will have a layer width(n) ghosts cells wide on either side of the visible data along the dimension n.
An example is shown in Figure "setirregdist" below .
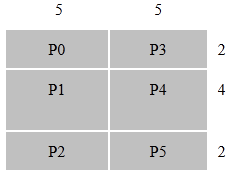
void GlobalArray::setMemoryDev(char *device)
| Type | Name | Description | Intent |
|---|---|---|---|
| char* | property | character string specifying the memory type | input |
Collective on the processor group inferred from the arguments.
This function allows users to specify what type of memory is used for allocating global arrays. This functionality relies on the Simpified Interface for Complex Memory library, available at https://github.com/lanl/SICM. If Global Arrays is not linked to SICM, then this property is ignored and the array will be allocated on ordinary memory. This should still produce correct code, but performance may be lower.
The type of memory available depends on the hardware being used. Currently supported options are "dram" (this is widely available but only corresponds to regular memory), "knl_hbm", and "ppc_hbm". The "hbm" options are high-bandwidth memory on the KNL and Power PC chips, respectively. If Global Arrays has not been compiled using SICM, the memory device option is ignored and a conventional global array is created.
void GlobalArray::setMemoryLimit(size_t limit);
| Type | Name | Description | Intent |
|---|---|---|---|
| size_t | limit | the amount of memory in bytes per process | input |
Local operation.
Sets the amount of memory to be used (in bytes) per process
void GlobalArray::setPGroup(PGroup *pHandle) const
| Type | Name | Description | Intent |
|---|---|---|---|
| PGroup* | pHandle | processor group instance | input |
Collective on the processor group inferred from the arguments.
This function can be used to set the processor configuration assigned to a global array handle that was obtained using the GA_Create_handle function. It can be used to create mirrored arrays by using the mirrored array processor configuration in this function call. It can also be used to create an array on a processor group by using a processor group handle in this call.
void GlobalArray::setProperty(char *property)
| Type | Name | Description | Intent |
|---|---|---|---|
| char* | property | character string representing the property | input |
Collective on the processor group inferred from the arguments.
This function allows users to assign properties to an array if there is advanced knowledge that an array will be used in a certain way. The two properties currently supported are "read_only" and "read_cache". These can both be set after the global array is allocated.
The read_only property is similar to creating a mirrored array in that the global array is replicated across an SMP node. This speeds up access to array data since all transfers can occur by shared memory copies on the same node. However, memory utilization increases since the global array is replicated across nodes even though it is distributed within a node. Setting the read_only property results in significant overhead since data for the array must be copied and redistributed. However, if the array is only used for read operations after initialization, this setting may be usefull in applications.
The read_cache property is useful when an application may be repeatedly accessing the same data. The read_cache property stores the recent blocks of data obtained via "get" operations. If a subsequent "get" requests the same data or a subset of the data, the data is obtained from the stored request instead of requesting it over the network. This can speed up performance if there are many duplicate requests for data. The total number of requests that are cached is limited and requests are stored in the cache on a first in, first out basis.
void GlobalArray::setRestricted(int list[], int nprocs) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | list | list of processors that should contain data | input |
| int | nprocs | number of processors in list | input |
Collective on the processor group inferred from the arguments.
This function restricts data in the global array g_a to only the nproc processors listed in the array list. The value of nproc must be less than or equal to the number of available processors. If this call is used in conjunction with GA_Set_irreg_distr, then the decomposition in the GA_Set_irreg_distr call must be done assuming that the number of processors is nproc. The data that ordinarily would be mapped to process 0 is mapped to the process in list[0], the data that would be mapped to process 1 will be mapped to list[1], etc. This can be used to remap the data distribution to different processors, even if nproc equals the number of available processors.
void GlobalArray::setRestrictedRange(int lo_proc, int hi_proc) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | lo_proc | low end of processor range | input |
| int | hi_proc | high end of processor range | input |
Collective on the processor group inferred from the arguments.
This function restricts data in the global array to the range of processors beginning with lo_proc and ending with hi_proc. Both lo_proc and hi_proc must be less than or equal to the total number of processors minus one (e.g., in the range [0,N-1], where N is the total number of processors) and lo_proc must be less than or equal to hi_proc. If lo_proc = 0 and hi_proc = N-1 then this call has no effect on the data distribution.
void GlobalArray::setTiledIrregProcGrid(int mapc[], int nblocks[], int proc_grid[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | mapc[] | starting index of each block | input |
| int | nblocks[] | array containing number of blocks in each dimension | input |
| int | proc_grid[] | processor grid dimensions | input |
Collective on the processor group inferred from the arguments.
This subroutine is a combination of the function that set an irregular distribution and the function for creating a tiled block-cyclic distribution. Like the conventional tiled block-cylic distribution, individual blocks are contiguous in memory. Unlike the conventional tiled distribution, individual blocks can vary in size. The mapc array consists of the starting index of each block along each dimension and the number of blocks along each axis is stored in the nblocks array. The number of entries in mapc equals the sum of the entries in nblocks. The proc_grid array describes how blocks are distributed over processors using a block-cylic distribution. The product of the entries in proc_grid is equal to the number of processors in the group that the global array is created on.
Note that the values in the nblocks arrays should be greater than or equal to the corresponding values in the proc_grid array.
void GlobalArray::setTiledProcGrid(int block_dims[], int proc_grid[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | block_dims | array of block dimensions | input |
| int* | proc_grid | processor grid dimensions | input |
Collective on the processor group inferred from the arguments.
This subroutine is used to create a global array with a SCALAPACK-type block cyclic data distribution but with individual blocks that are contiguous in memory. This layout may be preferable for algorithms that are moving single blocks of data since the corresponding messages will involve contiguous data transfers instead of strided calls. This may result in performance gains for communication bound programs. Otherwise, the data layout is similar to that created by the block-cyclic processor grid function.
The user specifies the dimensions of the processor grid in the array proc_grid. The product of the processor grid dimensions must equal the number of total number of processors and the number of dimensions in the processor grid must be the same as the number of dimensions in the global array. The data blocks are mapped onto the processor grid in a cyclic manner along each of the processor grid axes. The dimensions of individual blocks are located in the block_dims array.
void GlobalArray::shiftDiagonal(void *c) const
| Type | Name | Description | Intent |
|---|---|---|---|
| void* | c | double/complex/int/long/float constant to add | input |
Collective on the processor group inferred from the arguments.
Adds this constant to the diagonal elements of the matrix.
int GlobalArray::solve(const GlobalArray * g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_a | coefficient matrix | input |
Collective on the processor group inferred from the arguments.
Solves a system of linear equations
A * X = B
It first will call the Cholesky factorization routine and, if sucessfully, will solve the system with the Cholesky solver. If Cholesky will be not be able to factorize A, then it will call the LU factorization routine and will solve the system with forward/backward substitution. On exit B will contain the solution X.
It returns
= 0 : Cholesky factoriztion was succesful
> 0 : the leading minor of this order
is not positive definite, Cholesky factorization
could not be completed and LU factoriztion was used
int GlobalArray::spdInvert() const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | coefficient matrix | input |
Collective on the processor group inferred from the arguments.
It computes the inverse of a double precision using the Cholesky factorization of a NxN double precision symmetric positive definite matrix A stored in the global array represented by g_a. On successful exit, A will contain the inverse.
It returns
= 0 : successful exit
> 0 : the leading minor of this order is not positive
definite and the factorization could not be completed
< 0 : it returns the index i of the (i,i)
element of the factor L/U that is zero and
the inverse could not be computed
void GlobalArray::stepMax(const GlobalArray * g_b,
void *step) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_b | the step direction | input |
| void* | step | the maximum step | output |
Collective on the processor group inferred from the arguments.
Calculates the largest multiple of a vector g_b that can be added to this vector g_a while keeping each element of this vector non-negative.
void GlobalArray::stepMaxPatch(int *alo, int *ahi,
const GlobalArray *g_b, int *blo, int *bhi,
double *step) const
void GlobalArray::stepMaxPatch(
int64_t *alo, int64_t *ahi,
const GlobalArray *g_b, int64_t *blo, int64_t *bhi,
double *step) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_b | global array representing step direction | input |
| int* | alo | g_a lower corner patch coordinates | input |
| int* | ahi | g_a upper corner patch coordinates | input |
| int* | blo | g_b lower corner patch coordinates | input |
| int* | bhi | g_b upper corner patch coordinates | input |
Collective on the processor group inferred from the arguments.
Calculates the largest multiple of a vector g_b that can be added to this vector g_a while keeping each element of this vector non-negative.
void GlobalArray::stridedAcc(int lo[], int hi[], int skip[], void *buf,
int ld[], void *alpha) const;
void GlobalArray::stridedAcc(int64_t lo[], int64_t hi[], int64_t skip[],
void *buf, int64_t ld[], void *alpha) const;
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for glob array section | input |
| int* | hi[ndim] | array of ending indices for global array section | input |
| int* | skip[ndim] | array of strides for each dimension | input |
| void* | buf | pointer to local buffer array where data goes | input |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
| void* | alpha | double/DoubleComplex/long scale factor | input |
One-sided (non-collective).
This operation is the same as NGA_Acc, except that the values corresponding to dimension n in buf are accumulated to every skip[n] values of the global array g_a.
Combines data from buffer with data in the global array patch.
The buffer array is assumed to be have the same number of dimensions as the global array.
global array section (lo[],hi[]) += alpha * buffer
void GlobalArray::stridedGet(int lo[], int hi[], int skip[],
void *buf, int ld[]) const
void GlobalArray::stridedGet(int64_t lo[], int64_t hi[], int64_t skip[],
void *buf, int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for glob array section | input |
| int* | hi[ndim] | array of ending indices for global array section | input |
| int* | skip[ndim] | array of strides for each dimension | input |
| void* | buf | pointer to local buffer array where data goes | output |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
One-sided (non-collective).
This operation is the same as NGA_Get, except that the values corresponding to dimension n in buf correspond to every skip[n] values of the global array g_a.
The local array is assumed to be have the same number of dimensions as the global array. Any detected inconsitencies/errors in the input arguments are fatal.
Returns: The local array buffer.
void GlobalArray::stridedPut(int lo[], int hi[], int skip[],
void*buf, int ld[]) const
void GlobalArray::stridedPut(int64_t lo[], int64_t hi[], int64_t skip[],
void *buf, int64_t ld[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo[ndim] | array of starting indices for glob array section | input |
| int* | hi[ndim] | array of ending indices for global array section | input |
| int* | skip[ndim] | array of strides for each dimension | input |
| void* | buf | pointer to local buffer array where data goes | input |
| int* | ld[ndim-1] | array specifying leading dimensions/strides/extents for buffer array | input |
One-sided (non-collective).
Strided version of put. This operation is the same as NGA_Put, except that the values corresponding to dimension n in buf are copied to every skip[n] values of the global array g_a.
Copies data from local array buffer to the global array section.
The local array is assumed to be have the same number of dimensions as the global array.
Any detected inconsitencies/errors in input arguments are fatal.
void GlobalArray::summarize(int verbose) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | verbose | If true print distribution info | input |
Local operation.
Prints info about allocated arrays.
void GlobalArray::symmetrize() const
Collective on the processor group inferred from the arguments.
Symmetrizes matrix A represented with handle g_a: A:= .5 * (A+A').
GAServices::sync()
GA::sync()
Collective on the default processor group.
Synchronize processes (a barrier) and ensure that all GA operations completed.
void GA::Terminate()
Collective on the world processor group.
Delete all active arrays and destroy internal data structures.
int GlobalArray::totalBlocks() const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | total number of blocks in the block-cyclic distribution | output |
Local operation.
This function returns the total number of blocks contained in a global array with a block-cyclic data distribution.
void GlobalArray::transpose(const GlobalArray * g_a) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | g_a | assign transpose to this GlobalArray | input |
Collective on the processor group inferred from the arguments.
Transposes a matrix: B = A', where A and B are represented by handles g_a and g_b.
GAServices::unlock(int mutex)
| Type | Name | Description | Intent |
|---|---|---|---|
| int | mutex | mutex object id | input |
One-sided (non-collective).
Unlocks a mutex object identified by the mutex number. It is a fatal error for a process to attempt to unlock a mutex which has not been locked by this process.
void GlobalArray::unpack(GlobalArray *g_dest, GlobalArray *g_mask,
int lo, int hi, int *icount) const
void GlobalArray::unpack(GlobalArray *g_dest, GlobalArray *g_mask,
int64_t lo, int64_t hi, int64_t *icount) const
| Type | Name | Description | Intent |
|---|---|---|---|
| const GlobalArray* | g_dest | handle for destination array | input |
| const GlobalArray* | g_mask | handle for integer array representing mask | input |
| int | lo | low value of range on which operation is performed | input |
| int | hi | high value of range on which operation is performed | input |
| int* | icount | number of values in uncompressed array | output |
Collective on the processor group inferred from the arguments.
The unpack subroutine is designed to expand the values in the source vector g_src into a larger destination array g_dest based on the values in an integer mask array g_mask. The values lo and hi denote the range of elements that should be compressed and icount is a variable that on output lists the number of values placed in the uncompressed array. This operation is the complement of the GA_Pack operation. An example is shown below.
GA_Unpack(g_src, g_dest, g_mask, 1, n, &icount); g_src: 1 7 9 12 15 16 g_mask: 1 0 0 0 0 0 1 0 1 0 0 1 0 0 1 1 0 g_dest: 1 0 0 0 0 0 7 0 9 0 0 12 0 0 15 16 0 icount: 6
The current implementation requires that the distribution of the g_mask array matches the distribution of the g_dest array.
void GlobalArray::unsetProperty()
Collective on the processor group inferred from the arguments.
This function clears properties from the global array.
int GlobalArray::updateGhostDir(int dimension, int idir, int cflag) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int | dimension | array dimension that is to be updated | input |
| int | idir | direction of update (+/- 1) | input |
| int | cflag | flag (0/1) to include corners in update | input |
Collective on the processor group inferred from the arguments.
This function can be used to update the ghost cells along individual directions. It is designed for algorithms that can overlap updates with computation. The variable dimension indicates which coordinate direction is to be updated (e.g. dimension = 1 would correspond to the y axis in a two or three dimensional system), the variable idir can take the values +/-1 and indicates whether the side that is to be updated lies in the positive or negative direction, and cflag indicates whether or not the corners on the side being updated are to be included in the update. The following calls would be equivalent to a call to GA_Update_ghosts for a 2-dimensional system:
status = NGA_Update_ghost_dir(g_a,0,-1,1);
status = NGA_Update_ghost_dir(g_a,0,1,1);
status = NGA_Update_ghost_dir(g_a,1,-1,0);
status = NGA_Update_ghost_dir(g_a,1,1,0);
The variable cflag is set equal to 1 (or non-zero) in the first two calls so that the corner ghost cells are update, it is set equal to 0 in the second two calls to avoid redundant updates of the corners. Note that updating the ghosts cells using several independent calls to the nga_update_ghost_dir functions is generally not as efficient as using GA_Update_ghosts unless the individual calls can be effectively overlapped with computation.
void GlobalArray::updateGhosts() const
Collective on the processor group inferred from the arguments.
This call updates the ghost cell regions on each processor with the corresponding neighbor data from other processors. The operation assumes that all data is wrapped around using periodic boundary data so that ghost cell data that goes beyound an array boundary is wrapped around to the other end of the array. The GA_Update_ghosts call contains two GA_Sync calls before and after the actual update operation. For some applications these calls may be unecessary, if so they can be removed using the GA_Mask_sync subroutine.
int GlobalArray::usesMA()
Local operation.
Returns "1" if memory in global arrays comes from the Memory Allocator (MA). "0" means that memory comes from another source, for example System V shared memory is used.
TODO
double GlobalArray::wtime()
Local operation.
This function returns a wall (or elapsed) time on the calling processor. Returns time in seconds representing elapsed wall-clock time since an arbitrary time in the past. Example:
double starttime, endtime;
starttime = GA_Wtime();
.... code snippet to be timed ....
endtime = GA_Wtime();
printf("Time taken = %lf seconds\n", endtime-starttime);
This function is only available in release 4.1 or greater.
void GlobalArray::zero() const
Collective on the processor group inferred from the arguments.
Sets value of all elements in the array to zero.
void GlobalArray::zeroDiagonal() const
Collective on the processor group inferred from the arguments.
Sets the diagonal elements of this matrix g_a with zeros.
void GlobalArray::zeroPatch (int lo[], int hi[]) const
void GlobalArray::zeroPatch (int64_t lo[], int64_t hi[]) const
| Type | Name | Description | Intent |
|---|---|---|---|
| int* | lo | patch of this GlobalArray | input |
| int* | hi | patch of this GlobalArray | input |
Collective on the processor group inferred from the arguments.
Set all the elements in the patch to zero.