
SRUMMA: Highly Efficient and Scalable Parallel Matrix Multiplication Algorithm Exploiting Advanced Communication Protocols
Manojkumar Krishnan,
Jarek Nieplocha
Computational Sciences and Mathematics Division
Pacific Northwest National Laboratory
Richland, WA 99352
{manoj, jarek.nieplocha}@pnl.gov
For many scientific applications, dense matrix multiplication is one of the most important linear algebra operations. Because the optimized matrix multiplication can be extremely efficient, computational scientists routinely attempt to reformulate a mathematical description of their application in terms of matrix multiplications. Parallel matrix multiplication algorithms have been investigated for over two decades, with the currently leading SUMMA algorithm included in the ScaLAPACK and being predominantly used.
A novel algorithm, called SRUMMA [1] (Shared and Remote memory access based Universal Matrix Multiplication Algorithm), was developed as that provides a better performance and scalability on variety computer architectures than the leading algorithms used today. Unlike other algorithms that are based on message-passing, the new algorithm relies on ARMCI, a high performance remote memory access communication (one-sided communication) library developed under the DoE PModels project. In addition to the fast communication (shared memory, remote memory access nonblocking communication), the new algorithm relies on careful scheduling of communication operations to minimize contention in access to blocks of distributed matrices.
ARMCI exploits native network communication interfaces and system resources (such as shared memory, RDMA) to achieve the best possible performance of the remote memory access/one-sided communication. It exploits high-performance network protocols on clustered systems that use Myrinet, Quadrics, or Infiniband network.
The HP Linux cluster with Quadrics QSNET-II network utilizing 1960 1.5 GHz
Intel Itanium-2 processors at the Environmental Molecular Sciences Laboratory
at PNNL.
11.6TF Theoretical and 8.6TF Linpack peak performance for
Nmax=835000
Performance:
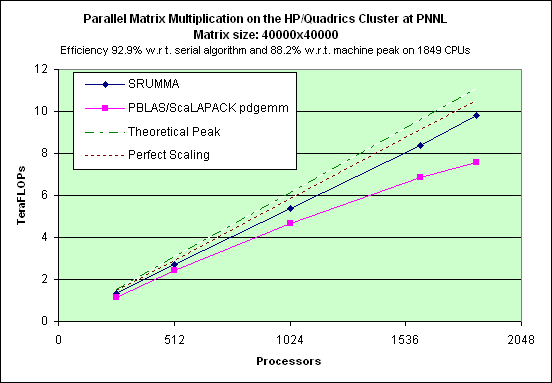
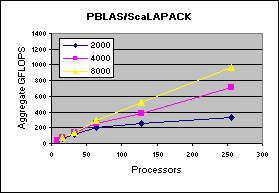
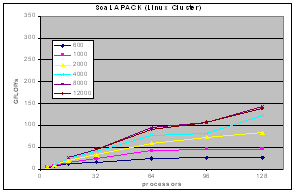
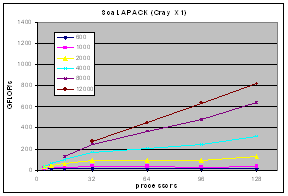
The experimental results on clusters (IBM SP, Linux-Myrinet, ....) and shared memory systems (SGI Altix, Cray X1) demonstrate consistent performance advantages over pdgemm from the ScaLAPACK/PBBLAS suite, the leading implementation of the parallel matrix multiplication algorithms used today. The impact of zero-copy nonblocking RMA (aka RDMA) communications and shared memory communication on matrix multiplication performance on clusters are investigated in [1,3].
| SRUMMA | ScaLAPACK | |
| 1.5 GHz IA64 Linux cluster with Quadrics QSNet2 network | 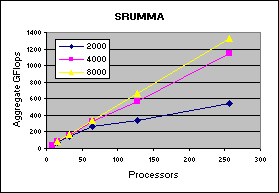 |
 |
| IA32 Linux cluster with Myrinet network | 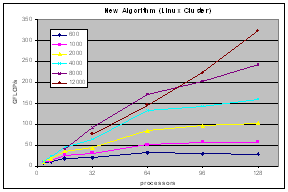 |
 |
| Cray X1 | 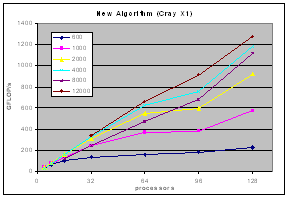 |
 |
| SGI Altix | 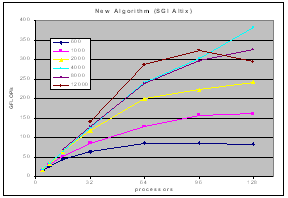 |
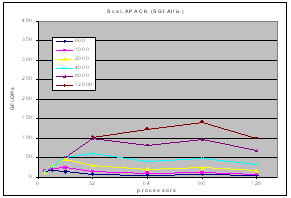 |
Publications:
- Manojkumar Krishnan and Jarek Nieplocha, “A Matrix Multiplication Algorithm Suitable for Clusters and Scalable Shared Memory Systems”, in proceedings of IEEE International Conference on Parallel and Distributed Processing Symposium’2004.
- M. Krishnan and J. Nieplocha, "Optimizing Parallel Multiplication Operation for Rectangular and Transposed Matrices," in Proceedings of 10th IEEE International Conference on Parallel and Distributed Systems (ICPADS'04). 2004.
- Manojkumar Krishnan and Jarek Nieplocha, "Optimizing Performance on Linux Clusters Using Advanced Communication Protocols: Achieving Over 10 Teraflops on a 8.6 Teraflops Linpack-Rated Linux Cluster", to appear in proceedings of International Conference on Linux clusters, 2005.
- Manojkumar Krishnan and Jarek Nieplocha, “Memory Efficient Parallel Martrix Multiplication Operation for Irregular Problems”, in proceedings of ACM SIGMICRO Computing Frontiers, 2006.
Source Code:
The ga_dgemm (using SRUMMA) source code is distributed with Global Arrays (GA) toolkit. Examples can be found in the global/testing directory of GA toolkit.
Contact:
If you have any questions regarding SRUMMA or using ga_dgemm(), please send an email to hpctools AT pnl DOT gov.