ARMCI Performance
The latency numbers below are for blocking operations. Nonblocking operations tend to provide better results depending on the benchmark used.
| Network Protocol | Latency Put (us) | Latency Get (us) |
| Shared Memory(Linux) | 0.162 | 0.160 |
| Myrinet-GM(2.4GHz Pentium-4, Linux 2.4, Myrinet C card, GM 1.64) | 12.8 | 17.8 |
| Quadrics Elan-3(1GHz ia64,Linux 2.4.20) | 4.71 | 6.42 |
| Quadrics Elan-4(1.4GHz AMD Opteron,Linux 2.4) | 1.80 | 2.66 |
| Quadrics Elan-4(1.5GHz ia64,Linux 2.4.20) | 2.45 | 4.56 |
| Infiniband(1GHz ia64,Linux 2.4.20) | 7.4 | 16.0 |
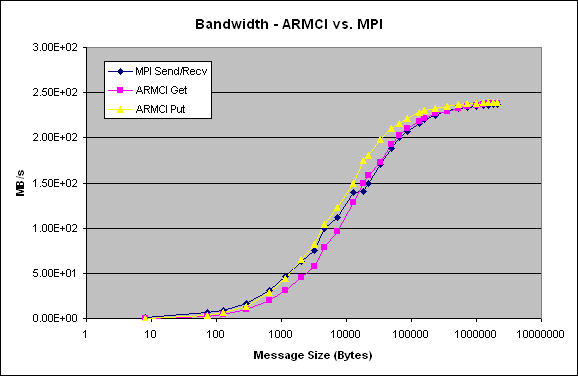
Myrinet-GM
Myrinet-GM (IA32)
Linux cluster with dual 2.4GHz Pentium-4 nodes, Myrinet-2000 (M3F-PCI64C-2 Myrinet interface) located at the State University of New York at Buffalo. It employs GM (1.6.4) and MPICH-GM libraries provided by Myricom.
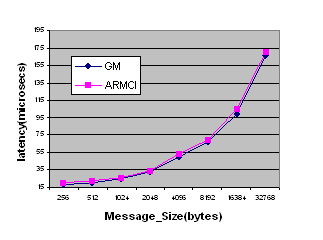
Comparison of latency of ARMCI get (nonblocking get followed by wait) operation with GM.
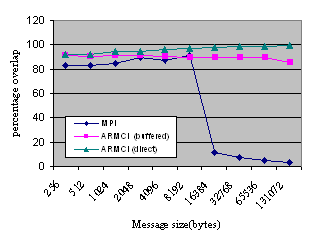
Non-blocking (overlapping communication with computation): % overlap for increasing message sizes for MPI and ARMCI (direct and server based protocols.
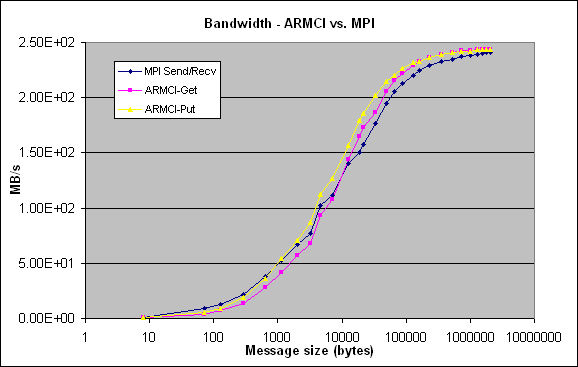
Myrinet-GM (IA64)
Linux cluster with dual 1 GHz Itanium-2 nodes, Myrinet-2000 ( M3F-PCI64B-2 Myrinet interface) located at Pacific Northwest National Laboratory. It employs GM (1.6.4) and MPICH-GM libraries provided by Myricom.