
SFT: Scalable Fault Tolerance
PROBLEM DESCRIPTION
As the number of processors for multi-teraflop systems grows to tens of thousands, with proposed petaflops systems likely to contain hundreds of thousands of processors, the assumption of fully reliable hardware and software has been abandoned. Although the mean time between failures for the individual components can be very high, the large total component count will inevitably lead to frequent failures. Also the status of a parallel machine can be extremely complex, with thousands of cooperating threads, which can have multiple outstanding messages in transit.
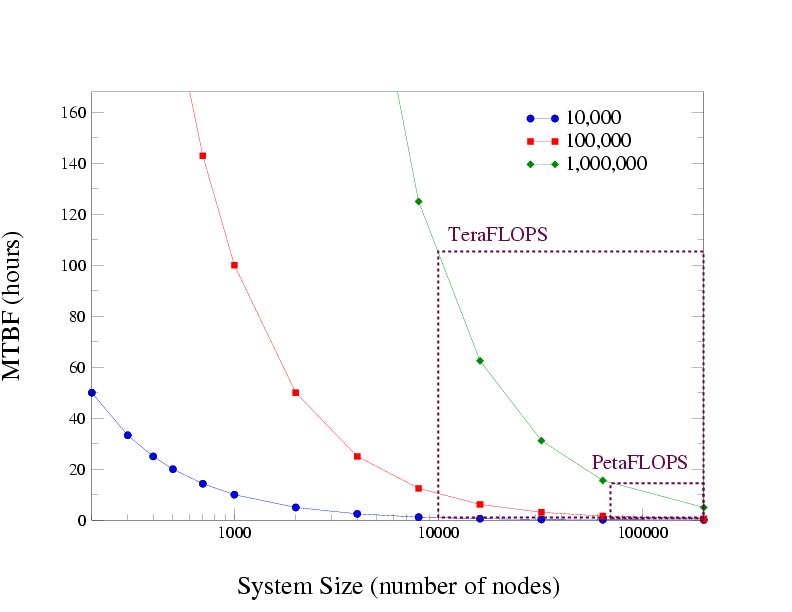
It is therefore of paramount importance to develop new system software solutions to deal with the unavoidable reality of hardware and software faults. The Figure below shows the expected mean time between failures (MTBF) obtained from a simple performance model for systems with three different component reliability levels: MTBFs ranging from 10,000 to 1 million hours. As can be seen, when increasing the number of components in the systemthe MTBF of the entire system dramatically decreases. For projected peta-flosp system, the MTBF is only a few hours even when all are of very high reliability (MTBF of 1 million hours).
PROPOSED SOLUTION
Our proposed solution is based on an automatic, frequent, user-transparent, and coordinated checkpoint and rollback-recovery mechanism. In essence, compute nodes are coordinated globally in order to checkpoint the computation state of the parallel program. In case of failure the non-functional portion of the machine is identified, a reallocation of resources is made, the compute nodes roll back to the most recently saved state, and the computation is continued.
Automatic and user-transparent checkpointing mechanisms are increasing in importance in large-scale parallel computing because the problems with user defined and managed checkpointing techniques only become worse with increasing system size.
We claim that highly scalable, highly efficient, transparent, and correct fault tolerance may be obtained using two mechanisms:
- Buffered CoScheduling (BCS) that enforces a sufficient degree of determinism on communication to make the design of efficient, scalable checkpointing algorithms tractable; and,
- Incremental checkpointing (TICK) that exploits the determinism imposed by Buffered CoScheduling. We implemented a prototype that performs incremental checkpointing in the Linux 2.6 kernel called TICK: Transparent Incremental Checkpointing at Kernel-level.