BCS: Buffered CoScheduling
OVERVIEW
Buffered CoScheduling is a new approach to the design of the communication layer for large scale parallel computers. The innovative contribution of BCS is that it imposes a specific degree of determinism on the scheduling of the communication in parallel applications.
BCS-MPI is an implementation of the BCS methodology. BCS-MPI orchestrates all communication activities at fixed intervals (timeslices) of a few hundreds of microseconds. At each interval communication is strictly scheduled: only the messages that can be delivered in a given interval and have been globally scheduled are injected to the network. Messages that require more than one interval are chunked in segments and scheduled over multiple intervals. The important aspect of this approach is that at the end of each interval the network is empty of messages. This guarantees that at certain known times during program execution there are no messages in transit; it is in this sense that determinism is imposed.
From the point of view of a checkpointing and rollback recovery mechanism this vastly simplifies the network state: the network is empty, all pending (portions of) messages are known, the remaining state is the set of memory images of the processes of the application, and the checkpointed data itself.
GLOBAL SYNCHRONIZATION PROTOCOL OF BCS_MPI
The implementation of this mechanism is based on a set of communication primitives (BCS core) which are tightly coupled with the primitives provided at hardware level by the network.
The performance and feasibility of this mechanism has been evaluated and validated on a preliminary prototype implemented at user (i.e. not OS) level with most of the code running on the NICs. It is expected that implementation at the system level, e.g. by a Linux kernel module, will be faster.
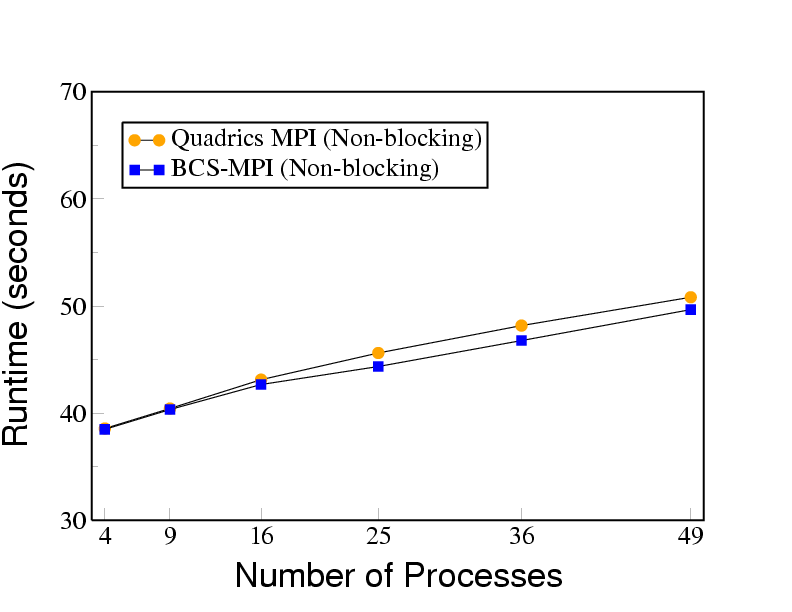
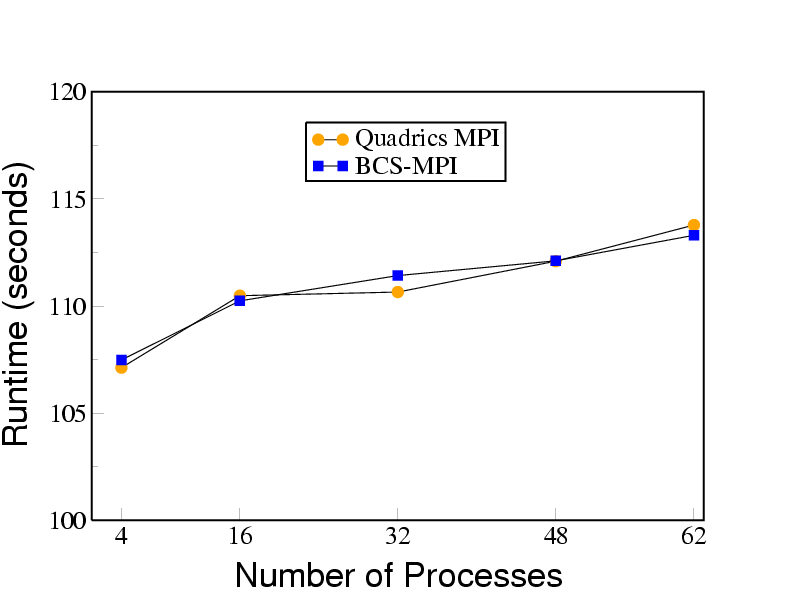
Despite the constrained communication of BCS-MPI, preliminary results reported for synthetic benchmarks shows that the loss of performance of the application is less than 7.5 percent with a computation granularity of 10ms on 62 processors.
Moreover, the slowdown significantly decreases when the computation granularity is increased because the delay introduced in communication is more than made up by increased time for computation.
Evaluation of the scalability of this mechanism has shown that the slowdown is almost unchanged by the number of processors in the system. The importance of this result is that it provides convincing evidence that BCS-MPI will exhibit very high scalability.
The Figures below show that the performance of BCS-MPI is very good.