
ChemIO: Disk Resident Arrays
Resident Arrays (DRA) extend the Global Arrays (GA) Non-Uniform Memory Access (NUMA) programming model to disk. The library encapsulates the details of data layout, addressing and I/O transfer in disk arrays objects. Disk resident arrays resemble global arrays except that they reside on the disk instead of the main memory.
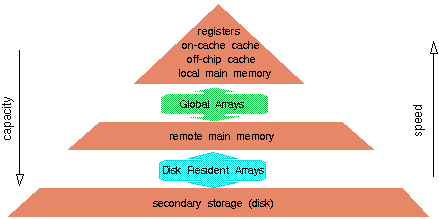
The Disk Arrays library is a part of a joint project between Pacific Northwest National Laboratory and Argonne National Laboratory on the parallel I/O for chemistry applications, ChemIO.
A paper describing DRA in more detail.
Documentation is available for all DRA functions and provides specific information about the programming interface.
Fortran interface C interfaceDisk Resident Arrays Model
- Data can be transfered (copied) between disk and global memory.
- I/O operations have nonblocking interface to allow overlapping of I/O with computations.
- All I/O operations are collective.
- Either whole or sections of global arrays can be transferred between GA memory and the disk.
- Reshaping and transpose operation are allowed during the transfer.
- Disk resident arrays might be temporary or persistent (saved after program termination and available in next runs).
- Persistent disk arrays can be accessed by any program executing on arbitrary number of processors.
- Distribution and internal data layout on the disk is optimized for large data transfer.
- Hints provided by the user are utilized to guide optimization of the library performance for the specific I/O patterns.
Generic Applications
Disk Resident Arrays can be employed to implement user-controlled virtual memory. Arrays that are to big to fit in the aggregate main memory of the system can be stored in Disk Array objects on the disk. Sections of the disk arrays can be transfered (cached) in main memory and used in the computations as needed.
Another possible application of disk resident arrays is checkpointing of programs that use distributed arrays.
Implementation Status
The Disk Resident Arrays library has been implemented on the Intel Paragon (PFS), IBM SP (PIOFS and local disks), Cray T3D, KSR-1, SGI Power Challenge, and networks of workstations. A public domain release of DRA library is planned for Fall of 1996.
Performance
In the benchmark, a 5000x5000 section of a 10000x10000 double precision matrix is copied between a distributed array (in memory) and disk resident array (stored on disk). Peformance of aligned and unaligned (w.r.t data layout on disk) requests is shown.
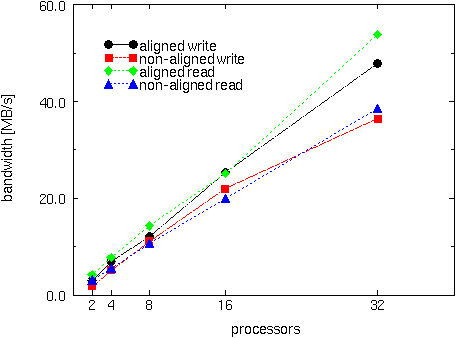 DRA Performance on the IBM SP-1.5 (local disk implementation)
DRA Performance on the IBM SP-1.5 (local disk implementation)
This figure shows performance of the implementation on top of multiple independent disks located at individual nodes of the IBM SP-1.5 at Argonne. As more processors are involved, the aggregate bandwidth grows since the DRA uses a larger number of disks. The AIX read/write bandwidth to each disk is 1.5-1.0 MB/s.
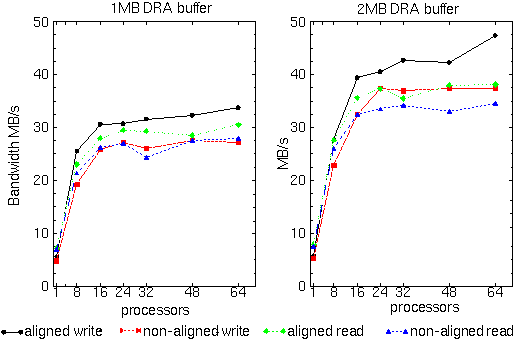 DRA performance on the Intel Paragon
DRA performance on the Intel Paragon
This figure shows the performance on a 512-node Intel Paragon at Caltech under PIOFS. The measurements were made in January 1996.